ocrd network: How to handle calls to unlisted processors? #1033
Description

@joschrew isn't that overly strict? We already have a long tail of processors, with new ones being added (continuously wrapping new external tools), so it's difficult to keep track of for admins even. (And we certainly should not enforce requiring the developers to "register" new processors centrally again.) So IIUC the
hostsentries are useful for preallocating/preloading a number if important processors, but there could still be a "let it fail" approach to unknown processors – simply trying to call their CLI when requested...
The way it currently works is: the processing-server is started with a configuration file. There the processors to be started are listet. This is the source of the mentioned
self.processor_list. Then for every processor a queue is created and this queue is used for a processor-call: A user request to a processor is accepted at the processing_server and it gets wrapped into a message to later start the processor run. So if the processor is not in that list it cannot be called because it has no queue related. Maybe you are thinking about the standalone processor as a server, that is not part of this branch.
Maybe you are thinking about the standalone processor as a server, that is not part of this branch.
No, I'm thinking of a fallback queue for all others processors to mitigate the problem that you have to (at any given time) know all processors in advance and configure them in the
hostssection.
Ah, ok understood, thanks for clearifying.
isn't that overly strict?
I think it is necessary for the current approach as we don't have the queue-on-demand-creation yet and therefore not available processors should be intercepted imo. Probably it should be thought about adding what you have in mind but tbh currently it is out of my scope.
Agreed. Should I open an issue in spec for this, @tdoan2010?
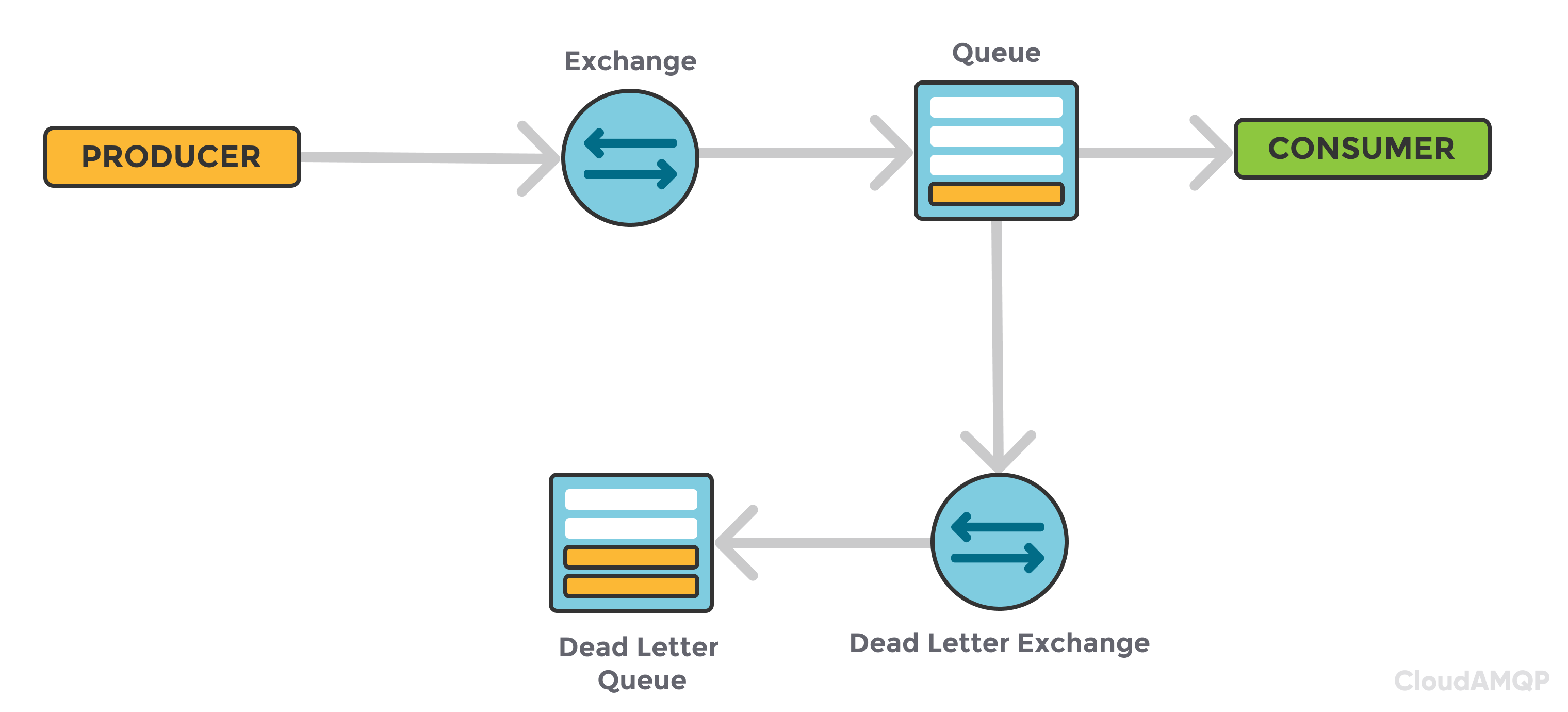
@bertsky, I am just seeing this conversation. I remember we already had an internal discussion (AFAIR, it's still not in the spec yet) about such a queue for storing processing messages that fail and can't be reprocessed. According to the current requirements, re-queuing a failing message creates an infinite loop. We still need to keep such messages somewhere (even if just for logging purposes) instead of silently dropping them. The general approach is to have a separate exchange agent which collects dropped (negatively acked by the consumer) messages and queues them to a separate dead letter queue. Check this diagram.
{kind=link}
@MehmedGIT that's not what this conversation was about, though. My concern was that we might not want to require setting up every possible processor runtime individually, but provide some sort of fallback (general purpose) worker that tries to feed these processing messages to the respective CLIs. So the processing server could then push all processing messages for non-configured processors into this fallback queue and hope for the best.
What you are addressing, however, is failing jobs (worker failing on the job). IMO nothing special should happen: the whole processing/workflow request should return failed in that case.
Rescheduling partially run workflows is another relatd topic BTW. So once the user fixed their workflow or runtime configuration, as long as the workspace is still present, the scheduler should identify which steps have already been run successfully before.
Sorry, somehow I missed this discussion because it is marked as "Outdated". But I agree with Robert. This check is not necessary. It actually restricts the ability to add more processors to the system at runtime.
Please remove this check.
The main issue here is that the dynamic deployment of processors was not envisioned in the architecture. Only processors specified inside the processing server configuration file are deployed. There is no way to deploy processors after starting the Processing Server. Hence, the current solution works according to these requirements. Ideally, a separate endpoint for deploying processors (not database or queue) should be implemented. After some refactoring of the deployer agent, implementing that is not complicated.
The main problem is the tracking of the run-time status of processing workers. In case a processing worker dies, the Processing Server or the Deployer has no way to check that (EDIT: no way, aka, it is not implemented yet.)
Only processors specified inside the processing server configuration file are deployed. There is no way to deploy processors after starting the Processing Server.
But @tdoan2010 is right: additional Processing Workers can be started outside and independent of the Processing Server at runtime. It would not be the responsibility of the latter to restart them (on failure) or shut them down (on termination), but of their outside controller, which could be some docker compose config btw. The Processing Server would not even have to know about them; rather, the (external) Processing Workers would have to know about the PS's queue and database, that's all.
The main problem is the tracking of the run-time status of processing workers. In case a processing worker dies, the Processing Server or the Deployer has no way to check that (EDIT: no way, aka, it is not implemented yet.)
But that's exactly the point of the discussion on worker failure...
But @tdoan2010 is right: additional Processing Workers can be started outside and independent of the Processing Server at runtime.
They can be started separately. But the processing server will have no info about them in order to terminate them.
It would not be the responsibility of the latter to restart them (on failure) or shut them down (on termination)
Well, exactly! But that was the initial idea - the processing server starting and killing all agents was envisioned. This is also in the current state of the spec. When the implementation has started it was easier to separate concepts, hence, they Deployer agent was introduced (although still not mentioned in the spec at all). Recently, it was decided to separate the Deployer completely.
Oh, you're right – so I was actually arguing in your favour here, and against dynamic deployment (i.e. keeping a mutable list of worker instances).
But what happened to that other, earlier idea of having some fallback queue (backed by special workers which simply try to run whatever CLI name was requested)? Would that be possible with RabbitMQ?
@bertsky, IMO not hard to implement with what we have currently. The processing worker has to be adapted. Currently, the processing server is creating the message queues to which the processing workers listen to. The processing server could also create an extra queue named "ocrd-default". Any processing requests that don't match to any other queue will be sent to that queue. Then the default worker could be started with
ocrd-defaultfor theprocessor-nameargument and start listening on that queue.However, the tricky part: During run-time if another specific worker of a specific processor is started that was not started with the config file and the processing server is not aware of that, the requests will still be going to the
ocrd-defaultqueue.And, honestly, I don't want to go in that direction by myself without having the required changes in the spec so potentially other problems that may arise are identified and discussed instead of trying to find fast hacky fixes on the fly afterwards.
However, the tricky part: During run-time if another specific worker of a specific processor is started that was not started with the config file and the processing server is not aware of that, the requests will still be going to the
ocrd-defaultqueue.Indeed! So here the two strategies would clash.
And, honestly, I don't want to go in that direction by myself without having the required changes in the spec so potentially other problems that may arise are identified and discussed instead of trying to find fast hacky fixes on the fly afterwards.
Ok, agreed. So let's deliberately leave the gap wide open – so we have a good reason to discuss openly afterwards.
We have not even entered the waters where the
processing-workercan be both a worker and a REST server according to the most recent spec changes. Check my comment here.