+  +
+
++ Evaluation framework for your Retrieval Augmented Generation (RAG) Pipelines Using Bedrock +
+ +
+
+  +
+
+
+
+
+ ![]() +
+
+
+
+
+  +
+
+
+
+
+ ![]() +
+
+
+
+
+
+
+
+
 +
+
+
+
+
+ Documentation | + Installation | + Quickstart | + Community | + Open Analytics | + Hugging Face +
+
+
+> 🚀 Dedicated solutions to evaluate, monitor and improve performance of LLM & RAG application in production including custom models for production quality monitoring.[Talk to founders](https://calendly.com/shahules/30min)
+
+Ragas is a framework that helps you evaluate your Retrieval Augmented Generation (RAG) pipelines. RAG denotes a class of LLM applications that use external data to augment the LLM’s context. There are existing tools and frameworks that help you build these pipelines but evaluating it and quantifying your pipeline performance can be hard. This is where Ragas (RAG Assessment) comes in.
+
+Ragas provides you with the tools based on the latest research for evaluating LLM-generated text to give you insights about your RAG pipeline. Ragas can be integrated with your CI/CD to provide continuous checks to ensure performance.
+
+## Table of Contents
+- [Architecture](#overview)
+- [Prerequisites and Setup](#prerequisites-and-setup)
+- [Usage and Examples](#usage-and-examples)
+- [Project Status](#project-status)
+- [Team](#team)
+
+## Architecture
+Below is a sample architecture for RAG evaluation. The RAGAS package for AWS projects will require the use of Bedrock.
+
+
+
+This diagram showcases:
+
+1. RAG QA bot being used to answer a user query
+
+2. The user providing ground truth for each of the queries
+
+3. Obtaining scores for specified metrics using Ragas
+
+4. Providing some sort of Error Correcting mechanism to improve the model based on the metrics. This is out of scope of this repository.
+
+5. Displaying Ragas outputs to some sort of application based on your use case. For example, you may want to use this as confidence that an LLM has outputted relevant and correct outputs.
+
+## :shield: Prerequisites and Setup
+
+```bash
+pip install ragas
+```
+
+if you want to install from source
+
+```bash
+git clone https://github.com/explodinggradients/ragas && cd ragas
+pip install -e .
+```
+
+## :fire: Usage and Examples
+
+This is a small example program you can run to see ragas in action!
+
+```python
+
+import sys
+sys.path.insert(0, '[path-to-ragas-folder]/src')
+
+from datasets import Dataset
+import os
+from ragas import evaluate
+from ragas.metrics import faithfulness, answer_correctness, context_precision, answer_similarity, [add any other metrics of interest]
+from langchain_aws.chat_models import ChatBedrock
+from langchain_community.embeddings import BedrockEmbeddings
+
+config = {
+ "region_name": "{add region name}", # E.g. "us-east-1"
+ "model_id": 'anthropic.claude-3-haiku-20240307-v1:0', # E.g "anthropic.claude-v2"
+ "model_kwargs": {"temperature": 0.4, "max_tokens": 5000}, # change max tokens if required
+}
+bedrock_model = ChatBedrock(
+ region_name=config["region_name"],
+ endpoint_url=f"https://bedrock-runtime.{config['region_name']}.amazonaws.com",
+ model_id=config["model_id"],
+ model_kwargs=config["model_kwargs"],
+)
+
+# init the embeddings, make sure you have access to the model
+bedrock_embeddings = BedrockEmbeddings(
+ model_id='amazon.titan-embed-text-v1,
+ region_name=config["region_name"],
+)
+
+data_samples = {
+ 'question': ['When was the first super bowl?', 'Who won the most super bowls?'],
+ 'answer': ['The first superbowl was held on Jan 15, 1967', 'The most super bowls have been won by The New England Patriots'],
+ 'contexts' : [['The First AFL–NFL World Championship Game was an American football game played on January 15, 1967, at the Los Angeles Memorial Coliseum in Los Angeles,'],
+ ['The Green Bay Packers...Green Bay, Wisconsin.','The Packers compete...Football Conference']],
+ 'ground_truth': ['The first superbowl was held on January 15, 1967', 'The New England Patriots have won the Super Bowl a record six times']
+}
+
+dataset = Dataset.from_dict(data_samples)
+
+score = evaluate(dataset,metrics=[faithfulness,answer_correctness, context_precision, answer_similarity], llm=bedrock_model,
+ embeddings=bedrock_embeddings)
+score.to_pandas()
+```
+Currently, there is an error when using Nova:
+ - ValidationException(An error occurred (ValidationException) when calling the Converse operation:
+ Invocation of model ID amazon.nova-lite-v1:0 with on-demand throughput isn’t supported.
+ Retry your request with the ID or ARN of an inference profile that contains this model
+
+Refer to our [documentation](https://docs.ragas.io/) to learn more.
+
+## Testing + Common Issues
+
+This repository is initially developed for OpenAI-based models but as shown in the usage and examples section, Bedrock can be easily integrated and for the most part, foundational models from Bedrock are able to correctly answer prompts and output them in the expected format. However, there are rare cases where issues can arise. Below are the two most common warnings/errors:
+
+```
+1. Failed to parse output. Returning None.
+2. Failed to parse output. Returning None." and "root -> 1 -> reason field required (type=value_error.missing)
+```
+
+The root of these errors comes from the expected output of the Bedrock foundational models which requires an output that is of JSON format, which for a few edge cases causes these errors. To debug, use Langsmith to visualize for each example the Bedrock outputs. Below is sample code to integrate Langsmith:
+
+```
+os.environ["LANGCHAIN_API_KEY"] =
+ +
+
+
+
+
+
+
+
+
+ user_input
+ retrieved_contexts
+ response
+ reference
+ hallucinations_metric
+ hallucinations_rubric
+ hallucinations_binary
+
+
+ 0
+ What are the global implications of the USA Su...
+ [- In 2022, the USA Supreme Court handed down ...
+ The global implications of the USA Supreme Cou...
+ The global implications of the USA Supreme Cou...
+ 0.423077
+ 3
+ 0
+
+
+ 1
+ Which companies are the main contributors to G...
+ [In recent years, there has been increasing pr...
+ According to the Carbon Majors database, the m...
+ According to the Carbon Majors database, the m...
+ 0.862069
+ 3
+ 0
+
+
+ 2
+ Which private companies in the Americas are th...
+ [The issue of greenhouse gas emissions has bec...
+ According to the Carbon Majors database, the l...
+ The largest private companies in the Americas ...
+ 1.000000
+ 3
+ 0
+
+
+ 3
+ What action did Amnesty International urge its...
+ [In the case of the Ogoni 9, Amnesty Internati...
+ Amnesty International urged its supporters to ...
+ Amnesty International urged its supporters to ...
+ 0.400000
+ 3
+ 0
+
+
+
+4
+ What are the recommendations made by Amnesty I...
+ [In recent years, Amnesty International has fo...
+ Amnesty International made several recommendat...
+ The recommendations made by Amnesty Internatio...
+ 0.952381
+ 3
+ 0
+ \n",
+ " \n",
+ "
\n",
+ "\n",
+ " \n",
+ " \n",
+ " \n",
+ " \n",
+ " user_input \n",
+ " retrieved_contexts \n",
+ " response \n",
+ " reference \n",
+ " hallucinations_metric \n",
+ " hallucinations_rubric \n",
+ " hallucinations_binary \n",
+ " \n",
+ " \n",
+ " 0 \n",
+ " What are the global implications of the USA Su... \n",
+ " [- In 2022, the USA Supreme Court handed down ... \n",
+ " The global implications of the USA Supreme Cou... \n",
+ " The global implications of the USA Supreme Cou... \n",
+ " 0.423077 \n",
+ " 3 \n",
+ " 0 \n",
+ " \n",
+ " \n",
+ " 1 \n",
+ " Which companies are the main contributors to G... \n",
+ " [In recent years, there has been increasing pr... \n",
+ " According to the Carbon Majors database, the m... \n",
+ " According to the Carbon Majors database, the m... \n",
+ " 0.862069 \n",
+ " 3 \n",
+ " 0 \n",
+ " \n",
+ " \n",
+ " 2 \n",
+ " Which private companies in the Americas are th... \n",
+ " [The issue of greenhouse gas emissions has bec... \n",
+ " According to the Carbon Majors database, the l... \n",
+ " The largest private companies in the Americas ... \n",
+ " 1.000000 \n",
+ " 3 \n",
+ " 0 \n",
+ " \n",
+ " \n",
+ " 3 \n",
+ " What action did Amnesty International urge its... \n",
+ " [In the case of the Ogoni 9, Amnesty Internati... \n",
+ " Amnesty International urged its supporters to ... \n",
+ " Amnesty International urged its supporters to ... \n",
+ " 0.400000 \n",
+ " 3 \n",
+ " 0 \n",
+ " \n",
+ " \n",
+ " \n",
+ "4 \n",
+ " What are the recommendations made by Amnesty I... \n",
+ " [In recent years, Amnesty International has fo... \n",
+ " Amnesty International made several recommendat... \n",
+ " The recommendations made by Amnesty Internatio... \n",
+ " 0.952381 \n",
+ " 3 \n",
+ " 0 \n",
+ "
+
+
+
+
+
+
+## Automatic Persona Generation
+
+If you want to automatically generate persona's from a knowledge graph, you can use the [generate_personas_from_kg][ragas.testset.persona.generate_personas_from_kg] function.
+
+
+
+```python
+from ragas.testset.persona import generate_personas_from_kg
+from ragas.testset.graph import KnowledgeGraph
+from ragas.llms import llm_factory
+
+kg = KnowledgeGraph.load("../../../../experiments/gitlab_kg.json")
+llm = llm_factory("gpt-4o-mini")
+
+personas = generate_personas_from_kg(kg=kg, llm=llm, num_personas=5)
+```
+
+
+```python
+personas
+```
+
+
+
+
+ [Persona(name='Organizational Development Manager', role_description='Responsible for implementing job frameworks and career development strategies to enhance employee growth and clarify roles within the company.'),
+ Persona(name='DevSecOps Product Manager', role_description='Responsible for overseeing the development and strategy of DevSecOps solutions, ensuring alignment with company goals and user needs.'),
+ Persona(name='Product Pricing Analyst', role_description='Responsible for developing and analyzing pricing strategies that align with customer needs and market demands.'),
+ Persona(name='Site Reliability Engineer', role_description='Responsible for maintaining service reliability and performance, focusing on implementing rate limits to prevent outages and enhance system stability.'),
+ Persona(name='Security Operations Engineer', role_description="Works on enhancing security logging processes and ensuring compliance within GitLab's infrastructure.")]
+
+
diff --git a/02-samples/17-multi-agent+evaluation-airline-assistant/taubench/src/ragas-evaluation/docs/howtos/customizations/testgenerator/_testgen-custom-single-hop.md b/02-samples/17-multi-agent+evaluation-airline-assistant/taubench/src/ragas-evaluation/docs/howtos/customizations/testgenerator/_testgen-custom-single-hop.md
new file mode 100644
index 00000000..2e843b1e
--- /dev/null
+++ b/02-samples/17-multi-agent+evaluation-airline-assistant/taubench/src/ragas-evaluation/docs/howtos/customizations/testgenerator/_testgen-custom-single-hop.md
@@ -0,0 +1,272 @@
+# Create custom single-hop queries from your documents
+
+### Load sample documents
+I am using documents from [gitlab handbook](https://huggingface.co/datasets/explodinggradients/Sample_Docs_Markdown). You can download it by running the below command.
+
+
+```python
+from langchain_community.document_loaders import DirectoryLoader
+
+
+path = "Sample_Docs_Markdown/"
+loader = DirectoryLoader(path, glob="**/*.md")
+docs = loader.load()
+```
+
+### Create KG
+
+Create a base knowledge graph with the documents
+
+
+```python
+from ragas.testset.graph import KnowledgeGraph
+from ragas.testset.graph import Node, NodeType
+
+
+kg = KnowledgeGraph()
+for doc in docs:
+ kg.nodes.append(
+ Node(
+ type=NodeType.DOCUMENT,
+ properties={
+ "page_content": doc.page_content,
+ "document_metadata": doc.metadata,
+ },
+ )
+ )
+```
+
+ /opt/homebrew/Caskroom/miniforge/base/envs/ragas/lib/python3.9/site-packages/tqdm/auto.py:21: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html
+ from .autonotebook import tqdm as notebook_tqdm
+
+
+### Set up the LLM and Embedding Model
+You may use any of [your choice](/docs/howtos/customizations/customize_models.md), here I am using models from open-ai.
+
+
+```python
+from ragas.llms.base import llm_factory
+from ragas.embeddings.base import embedding_factory
+
+llm = llm_factory()
+embedding = embedding_factory()
+```
+
+### Setup the transforms
+
+
+Here we are using 2 extractors and 2 relationship builders.
+- Headline extrator: Extracts headlines from the documents
+- Keyphrase extractor: Extracts keyphrases from the documents
+- Headline splitter: Splits the document into nodes based on headlines
+
+
+
+```python
+from ragas.testset.transforms import apply_transforms
+from ragas.testset.transforms import (
+ HeadlinesExtractor,
+ HeadlineSplitter,
+ KeyphrasesExtractor,
+)
+
+
+headline_extractor = HeadlinesExtractor(llm=llm)
+headline_splitter = HeadlineSplitter(min_tokens=300, max_tokens=1000)
+keyphrase_extractor = KeyphrasesExtractor(
+ llm=llm, property_name="keyphrases", max_num=10
+)
+```
+
+
+```python
+transforms = [
+ headline_extractor,
+ headline_splitter,
+ keyphrase_extractor,
+]
+
+apply_transforms(kg, transforms=transforms)
+```
+
+ Applying KeyphrasesExtractor: 6%| | 2/36 [00:01<00:20, 1Property 'keyphrases' already exists in node '514fdc'. Skipping!
+ Applying KeyphrasesExtractor: 11%| | 4/36 [00:01<00:10, 2Property 'keyphrases' already exists in node '84a0f6'. Skipping!
+ Applying KeyphrasesExtractor: 64%|▋| 23/36 [00:03<00:01, Property 'keyphrases' already exists in node '93f19d'. Skipping!
+ Applying KeyphrasesExtractor: 72%|▋| 26/36 [00:04<00:00, 1Property 'keyphrases' already exists in node 'a126bf'. Skipping!
+ Applying KeyphrasesExtractor: 81%|▊| 29/36 [00:04<00:00, Property 'keyphrases' already exists in node 'c230df'. Skipping!
+ Applying KeyphrasesExtractor: 89%|▉| 32/36 [00:04<00:00, 1Property 'keyphrases' already exists in node '4f2765'. Skipping!
+ Property 'keyphrases' already exists in node '4a4777'. Skipping!
+
+
+### Configure personas
+
+You can also do this automatically by using the [automatic persona generator](/docs/howtos/customizations/testgenerator/_persona_generator.md)
+
+
+```python
+from ragas.testset.persona import Persona
+
+person1 = Persona(
+ name="gitlab employee",
+ role_description="A junior gitlab employee curious on workings on gitlab",
+)
+persona2 = Persona(
+ name="Hiring manager at gitlab",
+ role_description="A hiring manager at gitlab trying to underestand hiring policies in gitlab",
+)
+persona_list = [person1, persona2]
+```
+
+##
+
+## SingleHop Query
+
+Inherit from `SingleHopQuerySynthesizer` and modify the function that generates scenarios for query creation.
+
+**Steps**:
+- find qualified set of nodes for the query creation. Here I am selecting all nodes with keyphrases extracted.
+- For each qualified set
+ - Match the keyphrase with one or more persona.
+ - Create all possible combinations of (Node, Persona, Query Style, Query Length)
+ - Samples the required number of queries from the combinations
+
+
+```python
+from ragas.testset.synthesizers.single_hop import (
+ SingleHopQuerySynthesizer,
+ SingleHopScenario,
+)
+from dataclasses import dataclass
+from ragas.testset.synthesizers.prompts import (
+ ThemesPersonasInput,
+ ThemesPersonasMatchingPrompt,
+)
+
+
+@dataclass
+class MySingleHopScenario(SingleHopQuerySynthesizer):
+
+ theme_persona_matching_prompt = ThemesPersonasMatchingPrompt()
+
+ async def _generate_scenarios(self, n, knowledge_graph, persona_list, callbacks):
+
+ property_name = "keyphrases"
+ nodes = []
+ for node in knowledge_graph.nodes:
+ if node.type.name == "CHUNK" and node.get_property(property_name):
+ nodes.append(node)
+
+ number_of_samples_per_node = max(1, n // len(nodes))
+
+ scenarios = []
+ for node in nodes:
+ if len(scenarios) >= n:
+ break
+ themes = node.properties.get(property_name, [""])
+ prompt_input = ThemesPersonasInput(themes=themes, personas=persona_list)
+ persona_concepts = await self.theme_persona_matching_prompt.generate(
+ data=prompt_input, llm=self.llm, callbacks=callbacks
+ )
+ base_scenarios = self.prepare_combinations(
+ node,
+ themes,
+ personas=persona_list,
+ persona_concepts=persona_concepts.mapping,
+ )
+ scenarios.extend(
+ self.sample_combinations(base_scenarios, number_of_samples_per_node)
+ )
+
+ return scenarios
+```
+
+
+```python
+query = MySingleHopScenario(llm=llm)
+```
+
+
+```python
+scenarios = await query.generate_scenarios(
+ n=5, knowledge_graph=kg, persona_list=persona_list
+)
+```
+
+
+```python
+scenarios[0]
+```
+
+
+
+
+ SingleHopScenario(
+ nodes=1
+ term=what is an ally
+ persona=name='Hiring manager at gitlab' role_description='A hiring manager at gitlab trying to underestand hiring policies in gitlab'
+ style=Web search like queries
+ length=long)
+
+
+
+
+```python
+result = await query.generate_sample(scenario=scenarios[-1])
+```
+
+### Modify prompt to customize the query style
+Here I am replacing the default prompt with an instruction to generate only Yes/No questions. This is an optional step.
+
+
+```python
+instruction = """Generate a Yes/No query and answer based on the specified conditions (persona, term, style, length)
+and the provided context. Ensure the answer is entirely faithful to the context, using only the information
+directly from the provided context.
+
+### Instructions:
+1. **Generate a Yes/No Query**: Based on the context, persona, term, style, and length, create a question
+that aligns with the persona's perspective, incorporates the term, and can be answered with 'Yes' or 'No'.
+2. **Generate an Answer**: Using only the content from the provided context, provide a 'Yes' or 'No' answer
+to the query. Do not add any information not included in or inferable from the context."""
+```
+
+
+```python
+prompt = query.get_prompts()["generate_query_reference_prompt"]
+prompt.instruction = instruction
+query.set_prompts(**{"generate_query_reference_prompt": prompt})
+```
+
+
+```python
+result = await query.generate_sample(scenario=scenarios[-1])
+```
+
+
+```python
+result.user_input
+```
+
+
+
+
+ 'Does the Diversity, Inclusion & Belonging (DIB) Team at GitLab have a structured approach to encourage collaborations among team members through various communication methods?'
+
+
+
+
+```python
+result.reference
+```
+
+
+
+
+ 'Yes'
+
+
+
+
+```python
+
+```
diff --git a/02-samples/17-multi-agent+evaluation-airline-assistant/taubench/src/ragas-evaluation/docs/howtos/customizations/testgenerator/_testgen-customisation.md b/02-samples/17-multi-agent+evaluation-airline-assistant/taubench/src/ragas-evaluation/docs/howtos/customizations/testgenerator/_testgen-customisation.md
new file mode 100644
index 00000000..39bb2958
--- /dev/null
+++ b/02-samples/17-multi-agent+evaluation-airline-assistant/taubench/src/ragas-evaluation/docs/howtos/customizations/testgenerator/_testgen-customisation.md
@@ -0,0 +1,273 @@
+# Create custom multi-hop queries from your documents
+
+In this tutorial you will get to learn how to create custom multi-hop queries from your documents. This is a very powerful feature that allows you to create queries that are not possible with the standard query types. This also helps you to create queries that are more specific to your use case.
+
+### Load sample documents
+I am using documents from [gitlab handbook](https://huggingface.co/datasets/explodinggradients/Sample_Docs_Markdown). You can download it by running the below command.
+
+
+```python
+! git clone https://huggingface.co/datasets/explodinggradients/Sample_Docs_Markdown
+```
+
+
+```python
+from langchain_community.document_loaders import DirectoryLoader, TextLoader
+
+path = "Sample_Docs_Markdown/"
+loader = DirectoryLoader(path, glob="**/*.md")
+docs = loader.load()
+```
+
+### Create KG
+
+Create a base knowledge graph with the documents
+
+
+```python
+from ragas.testset.graph import KnowledgeGraph
+from ragas.testset.graph import Node, NodeType
+
+
+kg = KnowledgeGraph()
+for doc in docs:
+ kg.nodes.append(
+ Node(
+ type=NodeType.DOCUMENT,
+ properties={
+ "page_content": doc.page_content,
+ "document_metadata": doc.metadata,
+ },
+ )
+ )
+```
+
+ /opt/homebrew/Caskroom/miniforge/base/envs/ragas/lib/python3.9/site-packages/tqdm/auto.py:21: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html
+ from .autonotebook import tqdm as notebook_tqdm
+
+
+### Set up the LLM and Embedding Model
+You may use any of [your choice](/docs/howtos/customizations/customize_models.md), here I am using models from open-ai.
+
+
+```python
+from ragas.llms.base import llm_factory
+from ragas.embeddings.base import embedding_factory
+
+llm = llm_factory()
+embedding = embedding_factory()
+```
+
+### Setup Extractors and Relationship builders
+
+To create multi-hop queries you need to undestand the set of documents that can be used for it. Ragas uses relationships between documents/nodes to quality nodes for creating multi-hop queries. To concretize, if Node A and Node B and conencted by a relationship (say entity or keyphrase overlap) then you can create a multi-hop query between them.
+
+Here we are using 2 extractors and 2 relationship builders.
+- Headline extrator: Extracts headlines from the documents
+- Keyphrase extractor: Extracts keyphrases from the documents
+- Headline splitter: Splits the document into nodes based on headlines
+- OverlapScore Builder: Builds relationship between nodes based on keyphrase overlap
+
+
+```python
+from ragas.testset.transforms import Parallel, apply_transforms
+from ragas.testset.transforms import (
+ HeadlinesExtractor,
+ HeadlineSplitter,
+ KeyphrasesExtractor,
+ OverlapScoreBuilder,
+)
+
+
+headline_extractor = HeadlinesExtractor(llm=llm)
+headline_splitter = HeadlineSplitter(min_tokens=300, max_tokens=1000)
+keyphrase_extractor = KeyphrasesExtractor(
+ llm=llm, property_name="keyphrases", max_num=10
+)
+relation_builder = OverlapScoreBuilder(
+ property_name="keyphrases",
+ new_property_name="overlap_score",
+ threshold=0.01,
+ distance_threshold=0.9,
+)
+```
+
+
+```python
+transforms = [
+ headline_extractor,
+ headline_splitter,
+ keyphrase_extractor,
+ relation_builder,
+]
+
+apply_transforms(kg, transforms=transforms)
+```
+
+ Applying KeyphrasesExtractor: 6%|██████▏ | 2/36 [00:01<00:17, 1.94it/s]Property 'keyphrases' already exists in node 'a2f389'. Skipping!
+ Applying KeyphrasesExtractor: 17%|██████████████████▋ | 6/36 [00:01<00:04, 6.37it/s]Property 'keyphrases' already exists in node '3068c0'. Skipping!
+ Applying KeyphrasesExtractor: 53%|██████████████████████████████████████████████████████████▌ | 19/36 [00:02<00:01, 8.88it/s]Property 'keyphrases' already exists in node '854bf7'. Skipping!
+ Applying KeyphrasesExtractor: 78%|██████████████████████████████████████████████████████████████████████████████████████▎ | 28/36 [00:03<00:00, 9.73it/s]Property 'keyphrases' already exists in node '2eeb07'. Skipping!
+ Property 'keyphrases' already exists in node 'd68f83'. Skipping!
+ Applying KeyphrasesExtractor: 83%|████████████████████████████████████████████████████████████████████████████████████████████▌ | 30/36 [00:03<00:00, 9.35it/s]Property 'keyphrases' already exists in node '8fdbea'. Skipping!
+ Applying KeyphrasesExtractor: 89%|██████████████████████████████████████████████████████████████████████████████████████████████████▋ | 32/36 [00:04<00:00, 7.76it/s]Property 'keyphrases' already exists in node 'ef6ae0'. Skipping!
+
+
+### Configure personas
+
+You can also do this automatically by using the [automatic persona generator](/docs/howtos/customizations/testgenerator/_persona_generator.md)
+
+
+```python
+from ragas.testset.persona import Persona
+
+person1 = Persona(
+ name="gitlab employee",
+ role_description="A junior gitlab employee curious on workings on gitlab",
+)
+persona2 = Persona(
+ name="Hiring manager at gitlab",
+ role_description="A hiring manager at gitlab trying to underestand hiring policies in gitlab",
+)
+persona_list = [person1, persona2]
+```
+
+### Create multi-hop query
+
+Inherit from `MultiHopQuerySynthesizer` and modify the function that generates scenarios for query creation.
+
+**Steps**:
+- find qualified set of (nodeA, relationship, nodeB) based on the relationships between nodes
+- For each qualified set
+ - Match the keyphrase with one or more persona.
+ - Create all possible combinations of (Nodes, Persona, Query Style, Query Length)
+ - Samples the required number of queries from the combinations
+
+
+
+```python
+from dataclasses import dataclass
+import typing as t
+from ragas.testset.synthesizers.multi_hop.base import (
+ MultiHopQuerySynthesizer,
+ MultiHopScenario,
+)
+from ragas.testset.synthesizers.prompts import (
+ ThemesPersonasInput,
+ ThemesPersonasMatchingPrompt,
+)
+
+
+@dataclass
+class MyMultiHopQuery(MultiHopQuerySynthesizer):
+
+ theme_persona_matching_prompt = ThemesPersonasMatchingPrompt()
+
+ async def _generate_scenarios(
+ self,
+ n: int,
+ knowledge_graph,
+ persona_list,
+ callbacks,
+ ) -> t.List[MultiHopScenario]:
+
+ # query and get (node_a, rel, node_b) to create multi-hop queries
+ results = kg.find_two_nodes_single_rel(
+ relationship_condition=lambda rel: (
+ True if rel.type == "keyphrases_overlap" else False
+ )
+ )
+
+ num_sample_per_triplet = max(1, n // len(results))
+
+ scenarios = []
+ for triplet in results:
+ if len(scenarios) < n:
+ node_a, node_b = triplet[0], triplet[-1]
+ overlapped_keywords = triplet[1].properties["overlapped_items"]
+ if overlapped_keywords:
+
+ # match the keyword with a persona for query creation
+ themes = list(dict(overlapped_keywords).keys())
+ prompt_input = ThemesPersonasInput(
+ themes=themes, personas=persona_list
+ )
+ persona_concepts = (
+ await self.theme_persona_matching_prompt.generate(
+ data=prompt_input, llm=self.llm, callbacks=callbacks
+ )
+ )
+
+ overlapped_keywords = [list(item) for item in overlapped_keywords]
+
+ # prepare and sample possible combinations
+ base_scenarios = self.prepare_combinations(
+ [node_a, node_b],
+ overlapped_keywords,
+ personas=persona_list,
+ persona_item_mapping=persona_concepts.mapping,
+ property_name="keyphrases",
+ )
+
+ # get number of required samples from this triplet
+ base_scenarios = self.sample_diverse_combinations(
+ base_scenarios, num_sample_per_triplet
+ )
+
+ scenarios.extend(base_scenarios)
+
+ return scenarios
+```
+
+
+```python
+query = MyMultiHopQuery(llm=llm)
+scenarios = await query.generate_scenarios(
+ n=10, knowledge_graph=kg, persona_list=persona_list
+)
+```
+
+
+```python
+scenarios[4]
+```
+
+
+
+
+ MultiHopScenario(
+ nodes=2
+ combinations=['Diversity Inclusion & Belonging', 'Diversity, Inclusion & Belonging Goals']
+ style=Web search like queries
+ length=short
+ persona=name='Hiring manager at gitlab' role_description='A hiring manager at gitlab trying to underestand hiring policies in gitlab')
+
+
+
+
+```python
+
+```
+
+### Run the multi-hop query
+
+
+```python
+result = await query.generate_sample(scenario=scenarios[-1])
+```
+
+
+```python
+result.user_input
+```
+
+
+
+
+ 'How does GitLab ensure that its DIB roundtables are effective in promoting diversity and inclusion?'
+
+
+
+Yay! You have created a multi-hop query. Now you can create any such queries by creating and exploring relationships between documents.
+
+##
diff --git a/02-samples/17-multi-agent+evaluation-airline-assistant/taubench/src/ragas-evaluation/docs/howtos/customizations/testgenerator/index.md b/02-samples/17-multi-agent+evaluation-airline-assistant/taubench/src/ragas-evaluation/docs/howtos/customizations/testgenerator/index.md
new file mode 100644
index 00000000..4fb9ce38
--- /dev/null
+++ b/02-samples/17-multi-agent+evaluation-airline-assistant/taubench/src/ragas-evaluation/docs/howtos/customizations/testgenerator/index.md
@@ -0,0 +1,3 @@
+# Customizing Test Data Generation
+
+Synthetic test generation can save a lot of time and effort in creating test datasets for evaluating AI applications. We are working on adding more support to customized test set generation. If you have any specific requirements or would like to collaborate on this, please [talk to us](https://cal.com/shahul-ragas/30min).
\ No newline at end of file
diff --git a/02-samples/17-multi-agent+evaluation-airline-assistant/taubench/src/ragas-evaluation/docs/howtos/customizations/testgenerator/language_adaptation.ipynb b/02-samples/17-multi-agent+evaluation-airline-assistant/taubench/src/ragas-evaluation/docs/howtos/customizations/testgenerator/language_adaptation.ipynb
new file mode 100644
index 00000000..67b3e7fe
--- /dev/null
+++ b/02-samples/17-multi-agent+evaluation-airline-assistant/taubench/src/ragas-evaluation/docs/howtos/customizations/testgenerator/language_adaptation.ipynb
@@ -0,0 +1,297 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Synthetic test generation from multi-lingual and cross-lingual corpus\n",
+ "\n",
+ "In this notebook, you'll learn how to adapt synthetic test data generation to multi-lingual (non english) and cross-lingual settings. For the sake of this tutorial, I am generating queries in Spanish from Spanish wikipedia articles. "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Download and Load corpus"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 1,
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "Cloning into 'Sample_non_english_corpus'...\n",
+ "remote: Enumerating objects: 12, done.\u001b[K\n",
+ "remote: Counting objects: 100% (8/8), done.\u001b[K\n",
+ "remote: Compressing objects: 100% (8/8), done.\u001b[K\n",
+ "remote: Total 12 (delta 0), reused 0 (delta 0), pack-reused 4 (from 1)\u001b[K\n",
+ "Unpacking objects: 100% (12/12), 11.43 KiB | 780.00 KiB/s, done.\n"
+ ]
+ }
+ ],
+ "source": [
+ "! git clone https://huggingface.co/datasets/explodinggradients/Sample_non_english_corpus"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 2,
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stderr",
+ "output_type": "stream",
+ "text": [
+ "/opt/homebrew/Caskroom/miniforge/base/envs/ragas/lib/python3.9/site-packages/requests/__init__.py:102: RequestsDependencyWarning: urllib3 (1.26.20) or chardet (5.2.0)/charset_normalizer (None) doesn't match a supported version!\n",
+ " warnings.warn(\"urllib3 ({}) or chardet ({})/charset_normalizer ({}) doesn't match a supported \"\n"
+ ]
+ }
+ ],
+ "source": [
+ "from langchain_community.document_loaders import DirectoryLoader, TextLoader\n",
+ "\n",
+ "\n",
+ "path = \"Sample_non_english_corpus/\"\n",
+ "loader = DirectoryLoader(path, glob=\"**/*.txt\")\n",
+ "docs = loader.load()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 3,
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/plain": [
+ "6"
+ ]
+ },
+ "execution_count": 3,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "len(docs)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Intialize required models"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 4,
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stderr",
+ "output_type": "stream",
+ "text": [
+ "/opt/homebrew/Caskroom/miniforge/base/envs/ragas/lib/python3.9/site-packages/tqdm/auto.py:21: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html\n",
+ " from .autonotebook import tqdm as notebook_tqdm\n"
+ ]
+ }
+ ],
+ "source": [
+ "from ragas.llms import LangchainLLMWrapper\n",
+ "from ragas.embeddings import LangchainEmbeddingsWrapper\n",
+ "from langchain_openai import ChatOpenAI\n",
+ "from langchain_openai import OpenAIEmbeddings\n",
+ "\n",
+ "generator_llm = LangchainLLMWrapper(ChatOpenAI(model=\"gpt-4o-mini\"))\n",
+ "generator_embeddings = LangchainEmbeddingsWrapper(OpenAIEmbeddings())"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Setup Persona and transforms\n",
+ "you may automatically create personas using this [notebook](./_persona_generator.md). For the sake of simplicity, I am using a pre-defined person, two basic tranforms and simple specic query distribution."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 16,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from ragas.testset.persona import Persona\n",
+ "\n",
+ "personas = [\n",
+ " Persona(\n",
+ " name=\"curious student\",\n",
+ " role_description=\"A student who is curious about the world and wants to learn more about different cultures and languages\",\n",
+ " ),\n",
+ "]"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from ragas.testset.transforms.extractors.llm_based import NERExtractor\n",
+ "from ragas.testset.transforms.splitters import HeadlineSplitter\n",
+ "\n",
+ "transforms = [HeadlineSplitter(), NERExtractor()]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Intialize test generator"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 17,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from ragas.testset import TestsetGenerator\n",
+ "\n",
+ "generator = TestsetGenerator(\n",
+ " llm=generator_llm, embedding_model=generator_embeddings, persona_list=personas\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Load and Adapt Queries\n",
+ "\n",
+ "Here we load the required query types and adapt them to the target language. "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 19,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from ragas.testset.synthesizers.single_hop.specific import (\n",
+ " SingleHopSpecificQuerySynthesizer,\n",
+ ")\n",
+ "\n",
+ "distribution = [\n",
+ " (SingleHopSpecificQuerySynthesizer(llm=generator_llm), 1.0),\n",
+ "]\n",
+ "\n",
+ "for query, _ in distribution:\n",
+ " prompts = await query.adapt_prompts(\"spanish\", llm=generator_llm)\n",
+ " query.set_prompts(**prompts)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Generate"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 20,
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stderr",
+ "output_type": "stream",
+ "text": [
+ "Applying HeadlineSplitter: 0%| | 0/6 [00:00\n",
+ "\n",
+ "
+
+
+
+
+ user_input
+ reference_contexts
+ reference
+ synthesizer_name
+
+
+ 0
+ What the Director do in GitLab and how they wo...
+ [09db4f3e-1c10-4863-9024-f869af48d3e0\n\ntitle...
+ The Director at GitLab, such as the Director o...
+ single_hop_specifc_query_synthesizer
+
+
+ 1
+ Wht is the rol of the VP in GitLab?
+ [56c84f1b-3558-4c80-b8a9-348e69a4801b\n\nJob F...
+ The VP, or Vice President, at GitLab is respon...
+ single_hop_specifc_query_synthesizer
+
+
+ 2
+ What GitLab do for career progression?
+ [ead619a5-930f-4e2b-b797-41927a04d2e3\n\nGoals...
+ The Job frameworks at GitLab help team members...
+ single_hop_specifc_query_synthesizer
+
+
+ 3
+ Wht is the S-grop and how do they work with ot...
+ [42babb12-b033-493f-b684-914e2b1b1d0f\n\nPeopl...
+ Members of the S-group are expected to demonst...
+ single_hop_specifc_query_synthesizer
+
+
+
+4
+ How does Google execute its company vision?
+ [c3ed463d-1cdc-4ba4-a6ca-2c4ab12da883\n\nof mo...
+ To effectively execute the company vision, man...
+ single_hop_specifc_query_synthesizer
+ \n",
+ " \n",
+ "
\n",
+ ""
+ ],
+ "text/plain": [
+ " user_input ... synthesizer_name\n",
+ "0 What the Director do in GitLab and how they wo... ... single_hop_specifc_query_synthesizer\n",
+ "1 Wht is the rol of the VP in GitLab? ... single_hop_specifc_query_synthesizer\n",
+ "2 What GitLab do for career progression? ... single_hop_specifc_query_synthesizer\n",
+ "3 Wht is the S-grop and how do they work with ot... ... single_hop_specifc_query_synthesizer\n",
+ "4 How does Google execute its company vision? ... single_hop_specifc_query_synthesizer\n",
+ "\n",
+ "[5 rows x 4 columns]"
+ ]
+ },
+ "execution_count": 15,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "testset.to_pandas().head()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Automatic Persona Generation\n",
+ "\n",
+ "If you want to automatically generate persona's from a knowledge graph, you can use the [generate_personas_from_kg][ragas.testset.persona.generate_personas_from_kg] function.\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from ragas.testset.persona import generate_personas_from_kg\n",
+ "from ragas.testset.graph import KnowledgeGraph\n",
+ "from ragas.llms import llm_factory\n",
+ "\n",
+ "kg = KnowledgeGraph.load(\"../../../../experiments/gitlab_kg.json\")\n",
+ "llm = llm_factory(\"gpt-4o-mini\")\n",
+ "\n",
+ "personas = generate_personas_from_kg(kg=kg, llm=llm, num_personas=5)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 12,
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/plain": [
+ "[Persona(name='Organizational Development Manager', role_description='Responsible for implementing job frameworks and career development strategies to enhance employee growth and clarify roles within the company.'),\n",
+ " Persona(name='DevSecOps Product Manager', role_description='Responsible for overseeing the development and strategy of DevSecOps solutions, ensuring alignment with company goals and user needs.'),\n",
+ " Persona(name='Product Pricing Analyst', role_description='Responsible for developing and analyzing pricing strategies that align with customer needs and market demands.'),\n",
+ " Persona(name='Site Reliability Engineer', role_description='Responsible for maintaining service reliability and performance, focusing on implementing rate limits to prevent outages and enhance system stability.'),\n",
+ " Persona(name='Security Operations Engineer', role_description=\"Works on enhancing security logging processes and ensuring compliance within GitLab's infrastructure.\")]"
+ ]
+ },
+ "execution_count": 12,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "personas"
+ ]
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "ragas",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.10.12"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 2
+}
diff --git a/02-samples/17-multi-agent+evaluation-airline-assistant/taubench/src/ragas-evaluation/docs/howtos/customizations/testgenerator/testgen-custom-single-hop.ipynb b/02-samples/17-multi-agent+evaluation-airline-assistant/taubench/src/ragas-evaluation/docs/howtos/customizations/testgenerator/testgen-custom-single-hop.ipynb
new file mode 100644
index 00000000..7829dd07
--- /dev/null
+++ b/02-samples/17-multi-agent+evaluation-airline-assistant/taubench/src/ragas-evaluation/docs/howtos/customizations/testgenerator/testgen-custom-single-hop.ipynb
@@ -0,0 +1,457 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "51c3407b-6041-4217-9ef9-a0e619a51603",
+ "metadata": {},
+ "source": [
+ "# Create custom single-hop queries from your documents"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "5fc18fe5",
+ "metadata": {},
+ "source": [
+ "### Load sample documents\n",
+ "I am using documents from [gitlab handbook](https://huggingface.co/datasets/explodinggradients/Sample_Docs_Markdown). You can download it by running the below command."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 2,
+ "id": "5e3647cd-f754-4f05-a5ea-488b6a6affaf",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from langchain_community.document_loaders import DirectoryLoader\n",
+ "\n",
+ "\n",
+ "path = \"Sample_Docs_Markdown/\"\n",
+ "loader = DirectoryLoader(path, glob=\"**/*.md\")\n",
+ "docs = loader.load()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "ba780919",
+ "metadata": {},
+ "source": [
+ "### Create KG\n",
+ "\n",
+ "Create a base knowledge graph with the documents"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 3,
+ "id": "9034eaf0-e6d8-41d1-943b-594331972f69",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stderr",
+ "output_type": "stream",
+ "text": [
+ "/opt/homebrew/Caskroom/miniforge/base/envs/ragas/lib/python3.9/site-packages/tqdm/auto.py:21: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html\n",
+ " from .autonotebook import tqdm as notebook_tqdm\n"
+ ]
+ }
+ ],
+ "source": [
+ "from ragas.testset.graph import KnowledgeGraph\n",
+ "from ragas.testset.graph import Node, NodeType\n",
+ "\n",
+ "\n",
+ "kg = KnowledgeGraph()\n",
+ "for doc in docs:\n",
+ " kg.nodes.append(\n",
+ " Node(\n",
+ " type=NodeType.DOCUMENT,\n",
+ " properties={\n",
+ " \"page_content\": doc.page_content,\n",
+ " \"document_metadata\": doc.metadata,\n",
+ " },\n",
+ " )\n",
+ " )"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "575e5725",
+ "metadata": {},
+ "source": [
+ "### Set up the LLM and Embedding Model\n",
+ "You may use any of [your choice](/docs/howtos/customizations/customize_models.md), here I am using models from open-ai."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 4,
+ "id": "52f6d1ae-c9ed-4d82-99d7-d130a36e41e8",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from ragas.llms.base import llm_factory\n",
+ "from ragas.embeddings.base import embedding_factory\n",
+ "\n",
+ "llm = llm_factory()\n",
+ "embedding = embedding_factory()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "af7f9eaa",
+ "metadata": {},
+ "source": [
+ "### Setup the transforms\n",
+ "\n",
+ "\n",
+ "Here we are using 2 extractors and 2 relationship builders.\n",
+ "- Headline extrator: Extracts headlines from the documents\n",
+ "- Keyphrase extractor: Extracts keyphrases from the documents\n",
+ "- Headline splitter: Splits the document into nodes based on headlines\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 5,
+ "id": "1308cf70-486c-4fc3-be9a-2401e9455312",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from ragas.testset.transforms import apply_transforms\n",
+ "from ragas.testset.transforms import (\n",
+ " HeadlinesExtractor,\n",
+ " HeadlineSplitter,\n",
+ " KeyphrasesExtractor,\n",
+ ")\n",
+ "\n",
+ "\n",
+ "headline_extractor = HeadlinesExtractor(llm=llm)\n",
+ "headline_splitter = HeadlineSplitter(min_tokens=300, max_tokens=1000)\n",
+ "keyphrase_extractor = KeyphrasesExtractor(\n",
+ " llm=llm, property_name=\"keyphrases\", max_num=10\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 6,
+ "id": "7eb5f52e-4f9f-4333-bc71-ec795bf5dfff",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stderr",
+ "output_type": "stream",
+ "text": [
+ "Applying KeyphrasesExtractor: 6%| | 2/36 [00:01<00:20, 1Property 'keyphrases' already exists in node '514fdc'. Skipping!\n",
+ "Applying KeyphrasesExtractor: 11%| | 4/36 [00:01<00:10, 2Property 'keyphrases' already exists in node '84a0f6'. Skipping!\n",
+ "Applying KeyphrasesExtractor: 64%|▋| 23/36 [00:03<00:01, Property 'keyphrases' already exists in node '93f19d'. Skipping!\n",
+ "Applying KeyphrasesExtractor: 72%|▋| 26/36 [00:04<00:00, 1Property 'keyphrases' already exists in node 'a126bf'. Skipping!\n",
+ "Applying KeyphrasesExtractor: 81%|▊| 29/36 [00:04<00:00, Property 'keyphrases' already exists in node 'c230df'. Skipping!\n",
+ "Applying KeyphrasesExtractor: 89%|▉| 32/36 [00:04<00:00, 1Property 'keyphrases' already exists in node '4f2765'. Skipping!\n",
+ "Property 'keyphrases' already exists in node '4a4777'. Skipping!\n",
+ " \r"
+ ]
+ }
+ ],
+ "source": [
+ "transforms = [\n",
+ " headline_extractor,\n",
+ " headline_splitter,\n",
+ " keyphrase_extractor,\n",
+ "]\n",
+ "\n",
+ "apply_transforms(kg, transforms=transforms)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "40503f3c",
+ "metadata": {},
+ "source": [
+ "### Configure personas\n",
+ "\n",
+ "You can also do this automatically by using the [automatic persona generator](/docs/howtos/customizations/testgenerator/_persona_generator.md)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 7,
+ "id": "213d93e7-1233-4df7-8022-4827b683f0b3",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from ragas.testset.persona import Persona\n",
+ "\n",
+ "person1 = Persona(\n",
+ " name=\"gitlab employee\",\n",
+ " role_description=\"A junior gitlab employee curious on workings on gitlab\",\n",
+ ")\n",
+ "persona2 = Persona(\n",
+ " name=\"Hiring manager at gitlab\",\n",
+ " role_description=\"A hiring manager at gitlab trying to underestand hiring policies in gitlab\",\n",
+ ")\n",
+ "persona_list = [person1, persona2]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "d5088c18-a8eb-4180-b066-46a8a795553b",
+ "metadata": {},
+ "source": [
+ "## "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "e3c756d2-1131-4fde-b3a7-b81589d15929",
+ "metadata": {},
+ "source": [
+ "## SingleHop Query\n",
+ "\n",
+ "Inherit from `SingleHopQuerySynthesizer` and modify the function that generates scenarios for query creation. \n",
+ "\n",
+ "**Steps**:\n",
+ "- find qualified set of nodes for the query creation. Here I am selecting all nodes with keyphrases extracted.\n",
+ "- For each qualified set\n",
+ " - Match the keyphrase with one or more persona. \n",
+ " - Create all possible combinations of (Node, Persona, Query Style, Query Length)\n",
+ " - Samples the required number of queries from the combinations"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 15,
+ "id": "c0a7128c-3840-434d-a1df-9e0835c2eb9b",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from ragas.testset.synthesizers.single_hop import (\n",
+ " SingleHopQuerySynthesizer,\n",
+ " SingleHopScenario,\n",
+ ")\n",
+ "from dataclasses import dataclass\n",
+ "from ragas.testset.synthesizers.prompts import (\n",
+ " ThemesPersonasInput,\n",
+ " ThemesPersonasMatchingPrompt,\n",
+ ")\n",
+ "\n",
+ "\n",
+ "@dataclass\n",
+ "class MySingleHopScenario(SingleHopQuerySynthesizer):\n",
+ "\n",
+ " theme_persona_matching_prompt = ThemesPersonasMatchingPrompt()\n",
+ "\n",
+ " async def _generate_scenarios(self, n, knowledge_graph, persona_list, callbacks):\n",
+ "\n",
+ " property_name = \"keyphrases\"\n",
+ " nodes = []\n",
+ " for node in knowledge_graph.nodes:\n",
+ " if node.type.name == \"CHUNK\" and node.get_property(property_name):\n",
+ " nodes.append(node)\n",
+ "\n",
+ " number_of_samples_per_node = max(1, n // len(nodes))\n",
+ "\n",
+ " scenarios = []\n",
+ " for node in nodes:\n",
+ " if len(scenarios) >= n:\n",
+ " break\n",
+ " themes = node.properties.get(property_name, [\"\"])\n",
+ " prompt_input = ThemesPersonasInput(themes=themes, personas=persona_list)\n",
+ " persona_concepts = await self.theme_persona_matching_prompt.generate(\n",
+ " data=prompt_input, llm=self.llm, callbacks=callbacks\n",
+ " )\n",
+ " base_scenarios = self.prepare_combinations(\n",
+ " node,\n",
+ " themes,\n",
+ " personas=persona_list,\n",
+ " persona_concepts=persona_concepts.mapping,\n",
+ " )\n",
+ " scenarios.extend(\n",
+ " self.sample_combinations(base_scenarios, number_of_samples_per_node)\n",
+ " )\n",
+ "\n",
+ " return scenarios"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 16,
+ "id": "6613ade2-b2bb-466a-800a-9ab8cad61661",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "query = MySingleHopScenario(llm=llm)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 17,
+ "id": "ca6f997f-355b-423f-8559-d20acfd11a53",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "scenarios = await query.generate_scenarios(\n",
+ " n=5, knowledge_graph=kg, persona_list=persona_list\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 19,
+ "id": "6622721d-74e1-4922-b68d-ce4c29a00c02",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/plain": [
+ "SingleHopScenario(\n",
+ "nodes=1\n",
+ "term=what is an ally\n",
+ "persona=name='Hiring manager at gitlab' role_description='A hiring manager at gitlab trying to underestand hiring policies in gitlab'\n",
+ "style=Web search like queries\n",
+ "length=long)"
+ ]
+ },
+ "execution_count": 19,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "scenarios[0]"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "ff32bf81",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "result = await query.generate_sample(scenario=scenarios[-1])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "bc5c0fb1",
+ "metadata": {},
+ "source": [
+ "### Modify prompt to customize the query style\n",
+ "Here I am replacing the default prompt with an instruction to generate only Yes/No questions. This is an optional step. "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 23,
+ "id": "6c5d43df-43ad-4ef4-9c52-37a943198400",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "instruction = \"\"\"Generate a Yes/No query and answer based on the specified conditions (persona, term, style, length) \n",
+ "and the provided context. Ensure the answer is entirely faithful to the context, using only the information \n",
+ "directly from the provided context.\n",
+ "\n",
+ "### Instructions:\n",
+ "1. **Generate a Yes/No Query**: Based on the context, persona, term, style, and length, create a question \n",
+ "that aligns with the persona's perspective, incorporates the term, and can be answered with 'Yes' or 'No'.\n",
+ "2. **Generate an Answer**: Using only the content from the provided context, provide a 'Yes' or 'No' answer \n",
+ "to the query. Do not add any information not included in or inferable from the context.\"\"\""
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 25,
+ "id": "4d20f2e7-7870-4dfe-acf1-05feb84adfe7",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "prompt = query.get_prompts()[\"generate_query_reference_prompt\"]\n",
+ "prompt.instruction = instruction\n",
+ "query.set_prompts(**{\"generate_query_reference_prompt\": prompt})"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 26,
+ "id": "855770c7-577b-41df-98c2-d366dd927008",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "result = await query.generate_sample(scenario=scenarios[-1])"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 27,
+ "id": "40254484-4e1d-450e-8d8b-3b9a20a00467",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/plain": [
+ "'Does the Diversity, Inclusion & Belonging (DIB) Team at GitLab have a structured approach to encourage collaborations among team members through various communication methods?'"
+ ]
+ },
+ "execution_count": 27,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "result.user_input"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 28,
+ "id": "916c1c5b-c92b-40cc-a1e8-d608e7c080f7",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/plain": [
+ "'Yes'"
+ ]
+ },
+ "execution_count": 28,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "result.reference"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "4d5fc423-e9e5-4493-b109-d3f5baac7eca",
+ "metadata": {},
+ "outputs": [],
+ "source": []
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "ragas",
+ "language": "python",
+ "name": "ragas"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.9.20"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/02-samples/17-multi-agent+evaluation-airline-assistant/taubench/src/ragas-evaluation/docs/howtos/customizations/testgenerator/testgen-customisation.ipynb b/02-samples/17-multi-agent+evaluation-airline-assistant/taubench/src/ragas-evaluation/docs/howtos/customizations/testgenerator/testgen-customisation.ipynb
new file mode 100644
index 00000000..ec835aea
--- /dev/null
+++ b/02-samples/17-multi-agent+evaluation-airline-assistant/taubench/src/ragas-evaluation/docs/howtos/customizations/testgenerator/testgen-customisation.ipynb
@@ -0,0 +1,444 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "51c3407b-6041-4217-9ef9-a0e619a51603",
+ "metadata": {},
+ "source": [
+ "# Create custom multi-hop queries from your documents\n",
+ "\n",
+ "In this tutorial you will get to learn how to create custom multi-hop queries from your documents. This is a very powerful feature that allows you to create queries that are not possible with the standard query types. This also helps you to create queries that are more specific to your use case."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "6d0a971b",
+ "metadata": {},
+ "source": [
+ "### Load sample documents\n",
+ "I am using documents from [gitlab handbook](https://huggingface.co/datasets/explodinggradients/Sample_Docs_Markdown). You can download it by running the below command."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "dd7e01c8",
+ "metadata": {
+ "vscode": {
+ "languageId": "plaintext"
+ }
+ },
+ "outputs": [],
+ "source": [
+ "! git clone https://huggingface.co/datasets/explodinggradients/Sample_Docs_Markdown"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 4,
+ "id": "5e3647cd-f754-4f05-a5ea-488b6a6affaf",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from langchain_community.document_loaders import DirectoryLoader, TextLoader\n",
+ "\n",
+ "path = \"Sample_Docs_Markdown/\"\n",
+ "loader = DirectoryLoader(path, glob=\"**/*.md\")\n",
+ "docs = loader.load()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "7db0c75d",
+ "metadata": {},
+ "source": [
+ "### Create KG\n",
+ "\n",
+ "Create a base knowledge graph with the documents"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 5,
+ "id": "9034eaf0-e6d8-41d1-943b-594331972f69",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stderr",
+ "output_type": "stream",
+ "text": [
+ "/opt/homebrew/Caskroom/miniforge/base/envs/ragas/lib/python3.9/site-packages/tqdm/auto.py:21: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html\n",
+ " from .autonotebook import tqdm as notebook_tqdm\n"
+ ]
+ }
+ ],
+ "source": [
+ "from ragas.testset.graph import KnowledgeGraph\n",
+ "from ragas.testset.graph import Node, NodeType\n",
+ "\n",
+ "\n",
+ "kg = KnowledgeGraph()\n",
+ "for doc in docs:\n",
+ " kg.nodes.append(\n",
+ " Node(\n",
+ " type=NodeType.DOCUMENT,\n",
+ " properties={\n",
+ " \"page_content\": doc.page_content,\n",
+ " \"document_metadata\": doc.metadata,\n",
+ " },\n",
+ " )\n",
+ " )"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "fa9b3f77",
+ "metadata": {},
+ "source": [
+ "### Set up the LLM and Embedding Model\n",
+ "You may use any of [your choice](/docs/howtos/customizations/customize_models.md), here I am using models from open-ai."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 6,
+ "id": "52f6d1ae-c9ed-4d82-99d7-d130a36e41e8",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from ragas.llms.base import llm_factory\n",
+ "from ragas.embeddings.base import embedding_factory\n",
+ "\n",
+ "llm = llm_factory()\n",
+ "embedding = embedding_factory()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "f22a543f",
+ "metadata": {},
+ "source": [
+ "### Setup Extractors and Relationship builders\n",
+ "\n",
+ "To create multi-hop queries you need to undestand the set of documents that can be used for it. Ragas uses relationships between documents/nodes to quality nodes for creating multi-hop queries. To concretize, if Node A and Node B and conencted by a relationship (say entity or keyphrase overlap) then you can create a multi-hop query between them.\n",
+ "\n",
+ "Here we are using 2 extractors and 2 relationship builders.\n",
+ "- Headline extrator: Extracts headlines from the documents\n",
+ "- Keyphrase extractor: Extracts keyphrases from the documents\n",
+ "- Headline splitter: Splits the document into nodes based on headlines\n",
+ "- OverlapScore Builder: Builds relationship between nodes based on keyphrase overlap"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 46,
+ "id": "1308cf70-486c-4fc3-be9a-2401e9455312",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from ragas.testset.transforms import Parallel, apply_transforms\n",
+ "from ragas.testset.transforms import (\n",
+ " HeadlinesExtractor,\n",
+ " HeadlineSplitter,\n",
+ " KeyphrasesExtractor,\n",
+ " OverlapScoreBuilder,\n",
+ ")\n",
+ "\n",
+ "\n",
+ "headline_extractor = HeadlinesExtractor(llm=llm)\n",
+ "headline_splitter = HeadlineSplitter(min_tokens=300, max_tokens=1000)\n",
+ "keyphrase_extractor = KeyphrasesExtractor(\n",
+ " llm=llm, property_name=\"keyphrases\", max_num=10\n",
+ ")\n",
+ "relation_builder = OverlapScoreBuilder(\n",
+ " property_name=\"keyphrases\",\n",
+ " new_property_name=\"overlap_score\",\n",
+ " threshold=0.01,\n",
+ " distance_threshold=0.9,\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 8,
+ "id": "7eb5f52e-4f9f-4333-bc71-ec795bf5dfff",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stderr",
+ "output_type": "stream",
+ "text": [
+ "Applying KeyphrasesExtractor: 6%|██████▏ | 2/36 [00:01<00:17, 1.94it/s]Property 'keyphrases' already exists in node 'a2f389'. Skipping!\n",
+ "Applying KeyphrasesExtractor: 17%|██████████████████▋ | 6/36 [00:01<00:04, 6.37it/s]Property 'keyphrases' already exists in node '3068c0'. Skipping!\n",
+ "Applying KeyphrasesExtractor: 53%|██████████████████████████████████████████████████████████▌ | 19/36 [00:02<00:01, 8.88it/s]Property 'keyphrases' already exists in node '854bf7'. Skipping!\n",
+ "Applying KeyphrasesExtractor: 78%|██████████████████████████████████████████████████████████████████████████████████████▎ | 28/36 [00:03<00:00, 9.73it/s]Property 'keyphrases' already exists in node '2eeb07'. Skipping!\n",
+ "Property 'keyphrases' already exists in node 'd68f83'. Skipping!\n",
+ "Applying KeyphrasesExtractor: 83%|████████████████████████████████████████████████████████████████████████████████████████████▌ | 30/36 [00:03<00:00, 9.35it/s]Property 'keyphrases' already exists in node '8fdbea'. Skipping!\n",
+ "Applying KeyphrasesExtractor: 89%|██████████████████████████████████████████████████████████████████████████████████████████████████▋ | 32/36 [00:04<00:00, 7.76it/s]Property 'keyphrases' already exists in node 'ef6ae0'. Skipping!\n",
+ " \r"
+ ]
+ }
+ ],
+ "source": [
+ "transforms = [\n",
+ " headline_extractor,\n",
+ " headline_splitter,\n",
+ " keyphrase_extractor,\n",
+ " relation_builder,\n",
+ "]\n",
+ "\n",
+ "apply_transforms(kg, transforms=transforms)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "b7da1d6d",
+ "metadata": {},
+ "source": [
+ "### Configure personas\n",
+ "\n",
+ "You can also do this automatically by using the [automatic persona generator](/docs/howtos/customizations/testgenerator/_persona_generator.md)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 79,
+ "id": "213d93e7-1233-4df7-8022-4827b683f0b3",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from ragas.testset.persona import Persona\n",
+ "\n",
+ "person1 = Persona(\n",
+ " name=\"gitlab employee\",\n",
+ " role_description=\"A junior gitlab employee curious on workings on gitlab\",\n",
+ ")\n",
+ "persona2 = Persona(\n",
+ " name=\"Hiring manager at gitlab\",\n",
+ " role_description=\"A hiring manager at gitlab trying to underestand hiring policies in gitlab\",\n",
+ ")\n",
+ "persona_list = [person1, persona2]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "ced43cb5",
+ "metadata": {},
+ "source": [
+ "### Create multi-hop query \n",
+ "\n",
+ "Inherit from `MultiHopQuerySynthesizer` and modify the function that generates scenarios for query creation. \n",
+ "\n",
+ "**Steps**:\n",
+ "- find qualified set of (nodeA, relationship, nodeB) based on the relationships between nodes\n",
+ "- For each qualified set\n",
+ " - Match the keyphrase with one or more persona. \n",
+ " - Create all possible combinations of (Nodes, Persona, Query Style, Query Length)\n",
+ " - Samples the required number of queries from the combinations\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 137,
+ "id": "08db4335-4b00-4f06-b855-4c847675a801",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from dataclasses import dataclass\n",
+ "import typing as t\n",
+ "from ragas.testset.synthesizers.multi_hop.base import (\n",
+ " MultiHopQuerySynthesizer,\n",
+ " MultiHopScenario,\n",
+ ")\n",
+ "from ragas.testset.synthesizers.prompts import (\n",
+ " ThemesPersonasInput,\n",
+ " ThemesPersonasMatchingPrompt,\n",
+ ")\n",
+ "\n",
+ "\n",
+ "@dataclass\n",
+ "class MyMultiHopQuery(MultiHopQuerySynthesizer):\n",
+ "\n",
+ " theme_persona_matching_prompt = ThemesPersonasMatchingPrompt()\n",
+ "\n",
+ " async def _generate_scenarios(\n",
+ " self,\n",
+ " n: int,\n",
+ " knowledge_graph,\n",
+ " persona_list,\n",
+ " callbacks,\n",
+ " ) -> t.List[MultiHopScenario]:\n",
+ "\n",
+ " # query and get (node_a, rel, node_b) to create multi-hop queries\n",
+ " results = kg.find_two_nodes_single_rel(\n",
+ " relationship_condition=lambda rel: (\n",
+ " True if rel.type == \"keyphrases_overlap\" else False\n",
+ " )\n",
+ " )\n",
+ "\n",
+ " num_sample_per_triplet = max(1, n // len(results))\n",
+ "\n",
+ " scenarios = []\n",
+ " for triplet in results:\n",
+ " if len(scenarios) < n:\n",
+ " node_a, node_b = triplet[0], triplet[-1]\n",
+ " overlapped_keywords = triplet[1].properties[\"overlapped_items\"]\n",
+ " if overlapped_keywords:\n",
+ "\n",
+ " # match the keyword with a persona for query creation\n",
+ " themes = list(dict(overlapped_keywords).keys())\n",
+ " prompt_input = ThemesPersonasInput(\n",
+ " themes=themes, personas=persona_list\n",
+ " )\n",
+ " persona_concepts = (\n",
+ " await self.theme_persona_matching_prompt.generate(\n",
+ " data=prompt_input, llm=self.llm, callbacks=callbacks\n",
+ " )\n",
+ " )\n",
+ "\n",
+ " overlapped_keywords = [list(item) for item in overlapped_keywords]\n",
+ "\n",
+ " # prepare and sample possible combinations\n",
+ " base_scenarios = self.prepare_combinations(\n",
+ " [node_a, node_b],\n",
+ " overlapped_keywords,\n",
+ " personas=persona_list,\n",
+ " persona_item_mapping=persona_concepts.mapping,\n",
+ " property_name=\"keyphrases\",\n",
+ " )\n",
+ "\n",
+ " # get number of required samples from this triplet\n",
+ " base_scenarios = self.sample_diverse_combinations(\n",
+ " base_scenarios, num_sample_per_triplet\n",
+ " )\n",
+ "\n",
+ " scenarios.extend(base_scenarios)\n",
+ "\n",
+ " return scenarios"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 138,
+ "id": "6935cdde-99c0-4893-8bd1-f72dc398eaee",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "query = MyMultiHopQuery(llm=llm)\n",
+ "scenarios = await query.generate_scenarios(\n",
+ " n=10, knowledge_graph=kg, persona_list=persona_list\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 151,
+ "id": "78fec1b9-f8a1-4237-9721-65bdae7059f8",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/plain": [
+ "MultiHopScenario(\n",
+ "nodes=2\n",
+ "combinations=['Diversity Inclusion & Belonging', 'Diversity, Inclusion & Belonging Goals']\n",
+ "style=Web search like queries\n",
+ "length=short\n",
+ "persona=name='Hiring manager at gitlab' role_description='A hiring manager at gitlab trying to underestand hiring policies in gitlab')"
+ ]
+ },
+ "execution_count": 151,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "scenarios[4]"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "49a38d27",
+ "metadata": {},
+ "outputs": [],
+ "source": []
+ },
+ {
+ "cell_type": "markdown",
+ "id": "61ae1d99",
+ "metadata": {},
+ "source": [
+ "### Run the multi-hop query"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 143,
+ "id": "da42bfb0-5122-4094-be22-6d6e74a9c0c0",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "result = await query.generate_sample(scenario=scenarios[-1])"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 144,
+ "id": "d4a865a7-b14b-4aa0-8def-128120cebae9",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/plain": [
+ "'How does GitLab ensure that its DIB roundtables are effective in promoting diversity and inclusion?'"
+ ]
+ },
+ "execution_count": 144,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "result.user_input"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "b716f1a5",
+ "metadata": {},
+ "source": [
+ "Yay! You have created a multi-hop query. Now you can create any such queries by creating and exploring relationships between documents."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "d5088c18-a8eb-4180-b066-46a8a795553b",
+ "metadata": {},
+ "source": [
+ "## "
+ ]
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "ragas",
+ "language": "python",
+ "name": "ragas"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.9.20"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/02-samples/17-multi-agent+evaluation-airline-assistant/taubench/src/ragas-evaluation/docs/howtos/index.md b/02-samples/17-multi-agent+evaluation-airline-assistant/taubench/src/ragas-evaluation/docs/howtos/index.md
new file mode 100644
index 00000000..5dcb2037
--- /dev/null
+++ b/02-samples/17-multi-agent+evaluation-airline-assistant/taubench/src/ragas-evaluation/docs/howtos/index.md
@@ -0,0 +1,31 @@
+# 🛠️ How-to Guides
+
+Each guide in this section provides a focused solution to real-world problems that you, as an experienced user, may encounter while using Ragas. These guides are designed to be concise and direct, offering quick solutions to your problems. We assume you have a foundational understanding and are comfortable with Ragas concepts. If not, feel free to explore the [Get Started](../getstarted/index.md) section first.
+
+\n",
+ " \n",
+ " \n",
+ " \n",
+ " \n",
+ " user_input \n",
+ " reference_contexts \n",
+ " reference \n",
+ " synthesizer_name \n",
+ " \n",
+ " \n",
+ " 0 \n",
+ " What the Director do in GitLab and how they wo... \n",
+ " [09db4f3e-1c10-4863-9024-f869af48d3e0\\n\\ntitle... \n",
+ " The Director at GitLab, such as the Director o... \n",
+ " single_hop_specifc_query_synthesizer \n",
+ " \n",
+ " \n",
+ " 1 \n",
+ " Wht is the rol of the VP in GitLab? \n",
+ " [56c84f1b-3558-4c80-b8a9-348e69a4801b\\n\\nJob F... \n",
+ " The VP, or Vice President, at GitLab is respon... \n",
+ " single_hop_specifc_query_synthesizer \n",
+ " \n",
+ " \n",
+ " 2 \n",
+ " What GitLab do for career progression? \n",
+ " [ead619a5-930f-4e2b-b797-41927a04d2e3\\n\\nGoals... \n",
+ " The Job frameworks at GitLab help team members... \n",
+ " single_hop_specifc_query_synthesizer \n",
+ " \n",
+ " \n",
+ " 3 \n",
+ " Wht is the S-grop and how do they work with ot... \n",
+ " [42babb12-b033-493f-b684-914e2b1b1d0f\\n\\nPeopl... \n",
+ " Members of the S-group are expected to demonst... \n",
+ " single_hop_specifc_query_synthesizer \n",
+ " \n",
+ " \n",
+ " \n",
+ "4 \n",
+ " How does Google execute its company vision? \n",
+ " [c3ed463d-1cdc-4ba4-a6ca-2c4ab12da883\\n\\nof mo... \n",
+ " To effectively execute the company vision, man... \n",
+ " single_hop_specifc_query_synthesizer \n",
+ "
+
+
+
+
+
+
+with a test dataset to test our `QueryEngine` lets now build one and evaluate it.
+
+## Building the `QueryEngine`
+
+To start lets build an `VectorStoreIndex` over the New York Citie's [wikipedia page](https://en.wikipedia.org/wiki/New_York_City) as an example and use ragas to evaluate it.
+
+Since we already loaded the dataset into `documents` lets use that.
+
+
+```python
+# build query engine
+from llama_index.core import VectorStoreIndex
+
+vector_index = VectorStoreIndex.from_documents(documents)
+
+query_engine = vector_index.as_query_engine()
+```
+
+Lets try an sample question from the generated testset to see if it is working
+
+
+```python
+# convert it to pandas dataset
+df = testset.to_pandas()
+df["user_input"][0]
+```
+
+
+
+
+ 'Cud yu pleese explane the role of New York City within the Northeast megalopolis, and how it contributes to the cultural and economic vibrancy of the region?'
+
+
+
+
+```python
+response_vector = query_engine.query(df["user_input"][0])
+
+print(response_vector)
+```
+
+ New York City serves as a key hub within the Northeast megalopolis, playing a significant role in enhancing the cultural and economic vibrancy of the region. Its status as a global center of creativity, entrepreneurship, and cultural diversity contributes to the overall dynamism of the area. The city's renowned arts scene, including Broadway theatre and numerous cultural institutions, attracts artists and audiences from around the world, enriching the cultural landscape of the Northeast megalopolis. Economically, New York City's position as a leading financial and fintech center, home to major stock exchanges and a bustling real estate market, bolsters the region's economic strength and influence. Additionally, the city's diverse culinary scene, influenced by its immigrant history, adds to the cultural richness of the region, making New York City a vital component of the Northeast megalopolis's cultural and economic tapestry.
+
+
+## Evaluating the `QueryEngine`
+
+Now that we have a `QueryEngine` for the `VectorStoreIndex` we can use the llama_index integration Ragas has to evaluate it.
+
+In order to run an evaluation with Ragas and LlamaIndex you need 3 things
+
+1. LlamaIndex `QueryEngine`: what we will be evaluating
+2. Metrics: Ragas defines a set of metrics that can measure different aspects of the `QueryEngine`. The available metrics and their meaning can be found [here](https://docs.ragas.io/en/latest/concepts/metrics/available_metrics/)
+3. Questions: A list of questions that ragas will test the `QueryEngine` against.
+
+first lets generate the questions. Ideally you should use that you see in production so that the distribution of question with which we evaluate matches the distribution of questions seen in production. This ensures that the scores reflect the performance seen in production but to start off we'll be using a few example question.
+
+Now lets import the metrics we will be using to evaluate
+
+
+```python
+# import metrics
+from ragas.metrics import (
+ Faithfulness,
+ AnswerRelevancy,
+ ContextPrecision,
+ ContextRecall,
+)
+
+# init metrics with evaluator LLM
+from ragas.llms import LlamaIndexLLMWrapper
+
+evaluator_llm = LlamaIndexLLMWrapper(OpenAI(model="gpt-4o"))
+metrics = [
+ Faithfulness(llm=evaluator_llm),
+ AnswerRelevancy(llm=evaluator_llm),
+ ContextPrecision(llm=evaluator_llm),
+ ContextRecall(llm=evaluator_llm),
+]
+```
+
+the `evaluate()` function expects a dict of "question" and "ground_truth" for metrics. You can easily convert the `testset` to that format
+
+
+```python
+# convert to Ragas Evaluation Dataset
+ragas_dataset = testset.to_evaluation_dataset()
+ragas_dataset
+```
+
+
+
+
+ EvaluationDataset(features=['user_input', 'reference_contexts', 'reference'], len=6)
+
+
+
+Finally lets run the evaluation
+
+
+```python
+from ragas.integrations.llama_index import evaluate
+
+result = evaluate(
+ query_engine=query_engine,
+ metrics=metrics,
+ dataset=ragas_dataset,
+)
+```
+
+
+```python
+# final scores
+print(result)
+```
+
+ {'faithfulness': 0.7454, 'answer_relevancy': 0.9348, 'context_precision': 0.6667, 'context_recall': 0.4667}
+
+
+You can convert into a pandas dataframe to run more analysis on it.
+
+
+```python
+result.to_pandas()
+```
+
+
+
+
+
+
+
+
+
+ user_input
+ reference_contexts
+ reference
+ synthesizer_name
+
+
+ 0
+ Cud yu pleese explane the role of New York Cit...
+ [New York, often called New York City or NYC, ...
+ New York City serves as the geographical and d...
+ single_hop_specifc_query_synthesizer
+
+
+ 1
+ So like, what was New York City called before ...
+ [History == === Early history === In the pre-C...
+ Before it was called New York, the area was kn...
+ single_hop_specifc_query_synthesizer
+
+
+ 2
+ what happen in new york with slavery and how i...
+ [and rechristened it "New Orange" after Willia...
+ In the early 18th century, New York became a c...
+ single_hop_specifc_query_synthesizer
+
+
+ 3
+ What historical significance does Long Island ...
+ [<1-hop>\n\nHistory == === Early history === I...
+ Long Island holds historical significance in t...
+ multi_hop_specific_query_synthesizer
+
+
+
+4
+ What role does the Staten Island Ferry play in...
+ [<1-hop>\n\nto start service in 2017; this wou...
+ The Staten Island Ferry plays a significant ro...
+ multi_hop_specific_query_synthesizer
+
+
+
+
+
+
+
+
+ user_input
+ retrieved_contexts
+ reference_contexts
+ response
+ reference
+ faithfulness
+ answer_relevancy
+ context_precision
+ context_recall
+
+
+ 0
+ Cud yu pleese explane the role of New York Cit...
+ [and its ideals of liberty and peace. In the 2...
+ [New York, often called New York City or NYC, ...
+ New York City plays a significant role within ...
+ New York City serves as the geographical and d...
+ 0.615385
+ 0.918217
+ 0.0
+ 0.0
+
+
+ 1
+ So like, what was New York City called before ...
+ [New York City is the headquarters of the glob...
+ [History == === Early history === In the pre-C...
+ New York City was named New Amsterdam before i...
+ Before it was called New York, the area was kn...
+ 1.000000
+ 0.967821
+ 1.0
+ 1.0
+
+
+ 2
+ what happen in new york with slavery and how i...
+ [=== Province of New York and slavery ===\n\nI...
+ [and rechristened it "New Orange" after Willia...
+ Slavery became a significant part of New York'...
+ In the early 18th century, New York became a c...
+ 1.000000
+ 0.919264
+ 1.0
+ 1.0
+
+
+ 3
+ What historical significance does Long Island ...
+ [==== River crossings ====\n\nNew York City is...
+ [<1-hop>\n\nHistory == === Early history === I...
+ Long Island played a significant role in the e...
+ Long Island holds historical significance in t...
+ 0.500000
+ 0.931895
+ 0.0
+ 0.0
+
+
+ 4
+ What role does the Staten Island Ferry play in...
+ [==== Buses ====\n\nNew York City's public bus...
+ [<1-hop>\n\nto start service in 2017; this wou...
+ The Staten Island Ferry serves as a vital mode...
+ The Staten Island Ferry plays a significant ro...
+ 0.500000
+ 0.936920
+ 1.0
+ 0.0
+
+
+
+5
+ How does Central Park's role as a cultural and...
+ [==== State parks ====\n\nThere are seven stat...
+ [<1-hop>\n\nCity has over 28,000 acres (110 km...
+ Central Park's role as a cultural and historic...
+ Central Park, located in middle-upper Manhatta...
+ 0.857143
+ 0.934841
+ 1.0
+ 0.8
+ 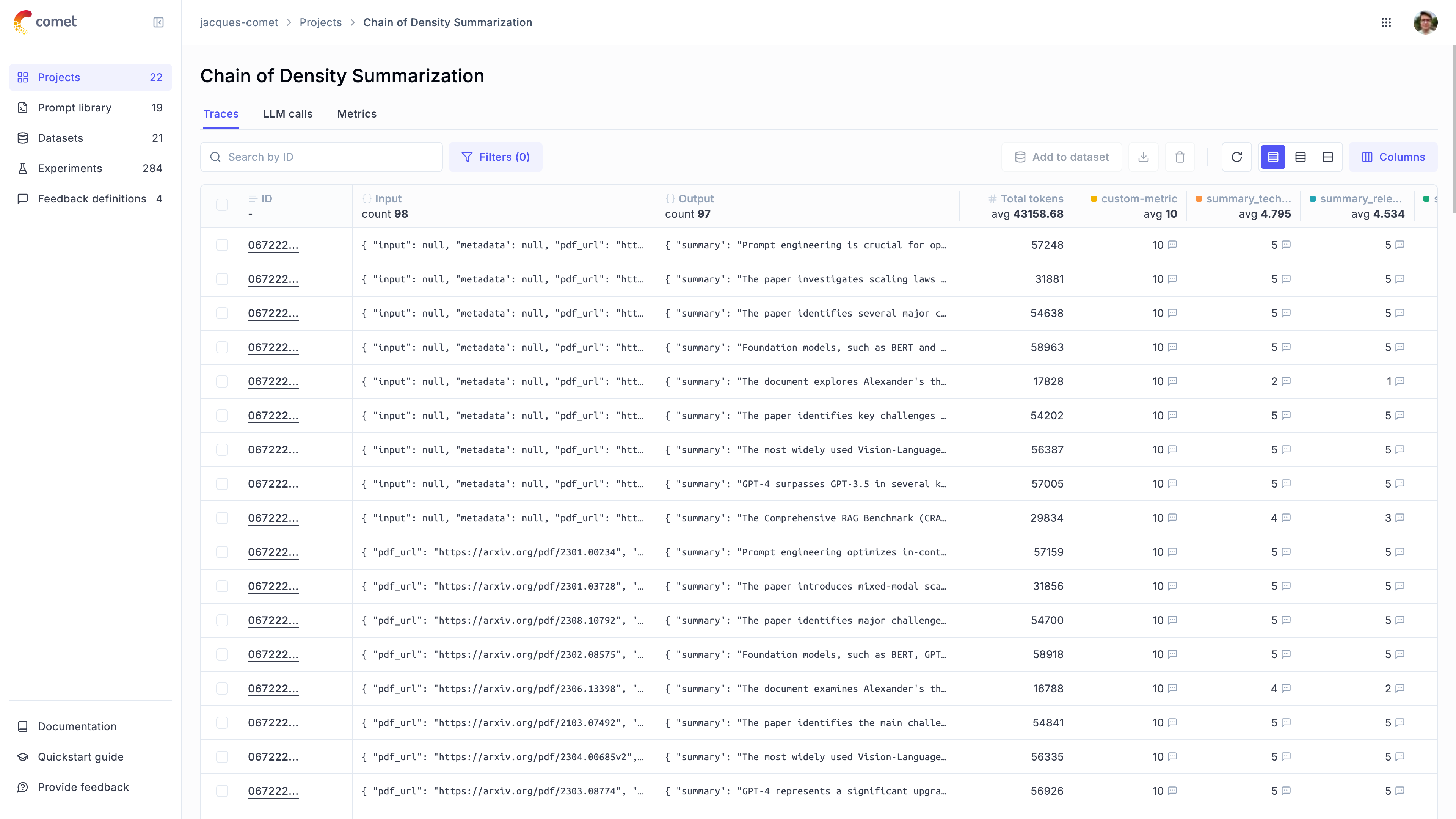
 +
+Validate makes it easy to understand the performance of your RAG or LLM application by visualizing and tracking over time the scores generated by Ragas. If you are already using Ragas today getting started is as easy as adding two additional lines of code into your python project.
+
+## Getting Started
+
+First create a [free validate account](https://validate.tonic.ai/signup). Once logged in, you'll need to create a new project. A project is typically associated to a single RAG or LLM application you wish to evaluate with Ragas. Once you've given your project a name you'll be taken to the project's new home page.
+
+To begin sending scores to Tonic Validate you'll need to install the tonic-ragas-logger package which is used to ship scores.
+
+```bash
+pip install tonic-ragas-logger
+```
+
+Now, in your existing python project you can add the below two lines of code to wherever you are running Ragas. This code will take the ```scores``` generated by Ragas' ```evaluate()``` function and ship the results to Tonic Validate. The API Key and Project ID referenced below are both available form your newly created project's home page.
+
+```python
+validate_api = RagasValidateApi("
+
+Validate makes it easy to understand the performance of your RAG or LLM application by visualizing and tracking over time the scores generated by Ragas. If you are already using Ragas today getting started is as easy as adding two additional lines of code into your python project.
+
+## Getting Started
+
+First create a [free validate account](https://validate.tonic.ai/signup). Once logged in, you'll need to create a new project. A project is typically associated to a single RAG or LLM application you wish to evaluate with Ragas. Once you've given your project a name you'll be taken to the project's new home page.
+
+To begin sending scores to Tonic Validate you'll need to install the tonic-ragas-logger package which is used to ship scores.
+
+```bash
+pip install tonic-ragas-logger
+```
+
+Now, in your existing python project you can add the below two lines of code to wherever you are running Ragas. This code will take the ```scores``` generated by Ragas' ```evaluate()``` function and ship the results to Tonic Validate. The API Key and Project ID referenced below are both available form your newly created project's home page.
+
+```python
+validate_api = RagasValidateApi("
+
+
+
\n",
+ " \n",
+ "
\n",
+ ""
+ ],
+ "text/plain": [
+ " user_input \\\n",
+ "0 Cud yu pleese explane the role of New York Cit... \n",
+ "1 So like, what was New York City called before ... \n",
+ "2 what happen in new york with slavery and how i... \n",
+ "3 What historical significance does Long Island ... \n",
+ "4 What role does the Staten Island Ferry play in... \n",
+ "\n",
+ " reference_contexts \\\n",
+ "0 [New York, often called New York City or NYC, ... \n",
+ "1 [History == === Early history === In the pre-C... \n",
+ "2 [and rechristened it \"New Orange\" after Willia... \n",
+ "3 [<1-hop>\\n\\nHistory == === Early history === I... \n",
+ "4 [<1-hop>\\n\\nto start service in 2017; this wou... \n",
+ "\n",
+ " reference \\\n",
+ "0 New York City serves as the geographical and d... \n",
+ "1 Before it was called New York, the area was kn... \n",
+ "2 In the early 18th century, New York became a c... \n",
+ "3 Long Island holds historical significance in t... \n",
+ "4 The Staten Island Ferry plays a significant ro... \n",
+ "\n",
+ " synthesizer_name \n",
+ "0 single_hop_specifc_query_synthesizer \n",
+ "1 single_hop_specifc_query_synthesizer \n",
+ "2 single_hop_specifc_query_synthesizer \n",
+ "3 multi_hop_specific_query_synthesizer \n",
+ "4 multi_hop_specific_query_synthesizer "
+ ]
+ },
+ "execution_count": 4,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "df = testset.to_pandas()\n",
+ "df.head()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "6107ea8b",
+ "metadata": {},
+ "source": [
+ "with a test dataset to test our `QueryEngine` lets now build one and evaluate it."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "abaf6538",
+ "metadata": {},
+ "source": [
+ "## Building the `QueryEngine`\n",
+ "\n",
+ "To start lets build an `VectorStoreIndex` over the New York Citie's [wikipedia page](https://en.wikipedia.org/wiki/New_York_City) as an example and use ragas to evaluate it. \n",
+ "\n",
+ "Since we already loaded the dataset into `documents` lets use that."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 5,
+ "id": "37c4a1cb",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# build query engine\n",
+ "from llama_index.core import VectorStoreIndex\n",
+ "\n",
+ "vector_index = VectorStoreIndex.from_documents(documents)\n",
+ "\n",
+ "query_engine = vector_index.as_query_engine()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "13d676c0",
+ "metadata": {},
+ "source": [
+ "Lets try an sample question from the generated testset to see if it is working"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 6,
+ "id": "895d95b2",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/plain": [
+ "'Cud yu pleese explane the role of New York City within the Northeast megalopolis, and how it contributes to the cultural and economic vibrancy of the region?'"
+ ]
+ },
+ "execution_count": 6,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "# convert it to pandas dataset\n",
+ "df = testset.to_pandas()\n",
+ "df[\"user_input\"][0]"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 7,
+ "id": "a25026c2",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "New York City serves as a key hub within the Northeast megalopolis, playing a significant role in enhancing the cultural and economic vibrancy of the region. Its status as a global center of creativity, entrepreneurship, and cultural diversity contributes to the overall dynamism of the area. The city's renowned arts scene, including Broadway theatre and numerous cultural institutions, attracts artists and audiences from around the world, enriching the cultural landscape of the Northeast megalopolis. Economically, New York City's position as a leading financial and fintech center, home to major stock exchanges and a bustling real estate market, bolsters the region's economic strength and influence. Additionally, the city's diverse culinary scene, influenced by its immigrant history, adds to the cultural richness of the region, making New York City a vital component of the Northeast megalopolis's cultural and economic tapestry.\n"
+ ]
+ }
+ ],
+ "source": [
+ "response_vector = query_engine.query(df[\"user_input\"][0])\n",
+ "\n",
+ "print(response_vector)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "b678501e",
+ "metadata": {},
+ "source": [
+ "## Evaluating the `QueryEngine`\n",
+ "\n",
+ "Now that we have a `QueryEngine` for the `VectorStoreIndex` we can use the llama_index integration Ragas has to evaluate it. \n",
+ "\n",
+ "In order to run an evaluation with Ragas and LlamaIndex you need 3 things\n",
+ "\n",
+ "1. LlamaIndex `QueryEngine`: what we will be evaluating\n",
+ "2. Metrics: Ragas defines a set of metrics that can measure different aspects of the `QueryEngine`. The available metrics and their meaning can be found [here](https://docs.ragas.io/en/latest/concepts/metrics/available_metrics/)\n",
+ "3. Questions: A list of questions that ragas will test the `QueryEngine` against. "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "145109ad",
+ "metadata": {},
+ "source": [
+ "first lets generate the questions. Ideally you should use that you see in production so that the distribution of question with which we evaluate matches the distribution of questions seen in production. This ensures that the scores reflect the performance seen in production but to start off we'll be using a few example question."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "843bddb8",
+ "metadata": {},
+ "source": [
+ "Now lets import the metrics we will be using to evaluate"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 8,
+ "id": "9875132a",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# import metrics\n",
+ "from ragas.metrics import (\n",
+ " Faithfulness,\n",
+ " AnswerRelevancy,\n",
+ " ContextPrecision,\n",
+ " ContextRecall,\n",
+ ")\n",
+ "\n",
+ "# init metrics with evaluator LLM\n",
+ "from ragas.llms import LlamaIndexLLMWrapper\n",
+ "\n",
+ "evaluator_llm = LlamaIndexLLMWrapper(OpenAI(model=\"gpt-4o\"))\n",
+ "metrics = [\n",
+ " Faithfulness(llm=evaluator_llm),\n",
+ " AnswerRelevancy(llm=evaluator_llm),\n",
+ " ContextPrecision(llm=evaluator_llm),\n",
+ " ContextRecall(llm=evaluator_llm),\n",
+ "]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "605e5d96",
+ "metadata": {},
+ "source": [
+ "the `evaluate()` function expects a dict of \"question\" and \"ground_truth\" for metrics. You can easily convert the `testset` to that format"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 9,
+ "id": "4b2a81ed",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/plain": [
+ "EvaluationDataset(features=['user_input', 'reference_contexts', 'reference'], len=6)"
+ ]
+ },
+ "execution_count": 9,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "# convert to Ragas Evaluation Dataset\n",
+ "ragas_dataset = testset.to_evaluation_dataset()\n",
+ "ragas_dataset"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "8ae4a2d1",
+ "metadata": {},
+ "source": [
+ "Finally lets run the evaluation"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "05633cc2",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from ragas.integrations.llama_index import evaluate\n",
+ "\n",
+ "result = evaluate(\n",
+ " query_engine=query_engine,\n",
+ " metrics=metrics,\n",
+ " dataset=ragas_dataset,\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 11,
+ "id": "f927a943",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "{'faithfulness': 0.7454, 'answer_relevancy': 0.9348, 'context_precision': 0.6667, 'context_recall': 0.4667}\n"
+ ]
+ }
+ ],
+ "source": [
+ "# final scores\n",
+ "print(result)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "878b6b82",
+ "metadata": {},
+ "source": [
+ "You can convert into a pandas dataframe to run more analysis on it."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 12,
+ "id": "b96311e2",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/html": [
+ "\n",
+ " \n",
+ " \n",
+ " \n",
+ " \n",
+ " user_input \n",
+ " reference_contexts \n",
+ " reference \n",
+ " synthesizer_name \n",
+ " \n",
+ " \n",
+ " 0 \n",
+ " Cud yu pleese explane the role of New York Cit... \n",
+ " [New York, often called New York City or NYC, ... \n",
+ " New York City serves as the geographical and d... \n",
+ " single_hop_specifc_query_synthesizer \n",
+ " \n",
+ " \n",
+ " 1 \n",
+ " So like, what was New York City called before ... \n",
+ " [History == === Early history === In the pre-C... \n",
+ " Before it was called New York, the area was kn... \n",
+ " single_hop_specifc_query_synthesizer \n",
+ " \n",
+ " \n",
+ " 2 \n",
+ " what happen in new york with slavery and how i... \n",
+ " [and rechristened it \"New Orange\" after Willia... \n",
+ " In the early 18th century, New York became a c... \n",
+ " single_hop_specifc_query_synthesizer \n",
+ " \n",
+ " \n",
+ " 3 \n",
+ " What historical significance does Long Island ... \n",
+ " [<1-hop>\\n\\nHistory == === Early history === I... \n",
+ " Long Island holds historical significance in t... \n",
+ " multi_hop_specific_query_synthesizer \n",
+ " \n",
+ " \n",
+ " \n",
+ "4 \n",
+ " What role does the Staten Island Ferry play in... \n",
+ " [<1-hop>\\n\\nto start service in 2017; this wou... \n",
+ " The Staten Island Ferry plays a significant ro... \n",
+ " multi_hop_specific_query_synthesizer \n",
+ " \n",
+ " \n",
+ "
\n",
+ "\n",
+ " \n",
+ " \n",
+ " \n",
+ " \n",
+ " user_input \n",
+ " retrieved_contexts \n",
+ " reference_contexts \n",
+ " response \n",
+ " reference \n",
+ " faithfulness \n",
+ " answer_relevancy \n",
+ " context_precision \n",
+ " context_recall \n",
+ " \n",
+ " \n",
+ " 0 \n",
+ " Cud yu pleese explane the role of New York Cit... \n",
+ " [and its ideals of liberty and peace. In the 2... \n",
+ " [New York, often called New York City or NYC, ... \n",
+ " New York City plays a significant role within ... \n",
+ " New York City serves as the geographical and d... \n",
+ " 0.615385 \n",
+ " 0.918217 \n",
+ " 0.0 \n",
+ " 0.0 \n",
+ " \n",
+ " \n",
+ " 1 \n",
+ " So like, what was New York City called before ... \n",
+ " [New York City is the headquarters of the glob... \n",
+ " [History == === Early history === In the pre-C... \n",
+ " New York City was named New Amsterdam before i... \n",
+ " Before it was called New York, the area was kn... \n",
+ " 1.000000 \n",
+ " 0.967821 \n",
+ " 1.0 \n",
+ " 1.0 \n",
+ " \n",
+ " \n",
+ " 2 \n",
+ " what happen in new york with slavery and how i... \n",
+ " [=== Province of New York and slavery ===\\n\\nI... \n",
+ " [and rechristened it \"New Orange\" after Willia... \n",
+ " Slavery became a significant part of New York'... \n",
+ " In the early 18th century, New York became a c... \n",
+ " 1.000000 \n",
+ " 0.919264 \n",
+ " 1.0 \n",
+ " 1.0 \n",
+ " \n",
+ " \n",
+ " 3 \n",
+ " What historical significance does Long Island ... \n",
+ " [==== River crossings ====\\n\\nNew York City is... \n",
+ " [<1-hop>\\n\\nHistory == === Early history === I... \n",
+ " Long Island played a significant role in the e... \n",
+ " Long Island holds historical significance in t... \n",
+ " 0.500000 \n",
+ " 0.931895 \n",
+ " 0.0 \n",
+ " 0.0 \n",
+ " \n",
+ " \n",
+ " 4 \n",
+ " What role does the Staten Island Ferry play in... \n",
+ " [==== Buses ====\\n\\nNew York City's public bus... \n",
+ " [<1-hop>\\n\\nto start service in 2017; this wou... \n",
+ " The Staten Island Ferry serves as a vital mode... \n",
+ " The Staten Island Ferry plays a significant ro... \n",
+ " 0.500000 \n",
+ " 0.936920 \n",
+ " 1.0 \n",
+ " 0.0 \n",
+ " \n",
+ " \n",
+ " \n",
+ "5 \n",
+ " How does Central Park's role as a cultural and... \n",
+ " [==== State parks ====\\n\\nThere are seven stat... \n",
+ " [<1-hop>\\n\\nCity has over 28,000 acres (110 km... \n",
+ " Central Park's role as a cultural and historic... \n",
+ " Central Park, located in middle-upper Manhatta... \n",
+ " 0.857143 \n",
+ " 0.934841 \n",
+ " 1.0 \n",
+ " 0.8 \n",
+ " 
 \n",
+ "\n",
+ "Validate makes it easy to understand the performance of your RAG or LLM application by visualizing and tracking over time the scores generated by Ragas. If you are already using Ragas today getting started is as easy as adding two additional lines of code into your python project.\n",
+ "\n",
+ "## Getting Started\n",
+ "\n",
+ "First create a [free validate account](https://validate.tonic.ai/signup). Once logged in, you'll need to create a new project. A project is typically associated to a single RAG or LLM application you wish to evaluate with Ragas. Once you've given your project a name you'll be taken to the project's new home page.\n",
+ "\n",
+ "To begin sending scores to Tonic Validate you'll need to install the tonic-ragas-logger package which is used to ship scores.\n",
+ "\n",
+ "```bash\n",
+ "pip install tonic-ragas-logger\n",
+ "```\n",
+ "\n",
+ "Now, in your existing python project you can add the below two lines of code to wherever you are running Ragas. This code will take the ```scores``` generated by Ragas' ```evaluate()``` function and ship the results to Tonic Validate. The API Key and Project ID referenced below are both available form your newly created project's home page.\n",
+ "\n",
+ "```python\n",
+ "validate_api = RagasValidateApi(\"
\n",
+ "\n",
+ "Validate makes it easy to understand the performance of your RAG or LLM application by visualizing and tracking over time the scores generated by Ragas. If you are already using Ragas today getting started is as easy as adding two additional lines of code into your python project.\n",
+ "\n",
+ "## Getting Started\n",
+ "\n",
+ "First create a [free validate account](https://validate.tonic.ai/signup). Once logged in, you'll need to create a new project. A project is typically associated to a single RAG or LLM application you wish to evaluate with Ragas. Once you've given your project a name you'll be taken to the project's new home page.\n",
+ "\n",
+ "To begin sending scores to Tonic Validate you'll need to install the tonic-ragas-logger package which is used to ship scores.\n",
+ "\n",
+ "```bash\n",
+ "pip install tonic-ragas-logger\n",
+ "```\n",
+ "\n",
+ "Now, in your existing python project you can add the below two lines of code to wherever you are running Ragas. This code will take the ```scores``` generated by Ragas' ```evaluate()``` function and ship the results to Tonic Validate. The API Key and Project ID referenced below are both available form your newly created project's home page.\n",
+ "\n",
+ "```python\n",
+ "validate_api = RagasValidateApi(\"
\n",
+ "
\n",
+ "\n",
+ "