- DYNAMODB PROJESİ
- SQL VE NoSQL Farkları
-
Projemde .env kullandım. Normalde gizli olarak gönderilmesi gereken bu dosyayı projenin sorunsuz çalışması için açık bir şekilde yolladım. .env dosyasına dynamoDB bilgilerini şu formatta girmelisiniz.
ACCESS_KEY_ID= Sizin id'niz
SECRET_ACCESS_KEY= Sizin key'iniz
Verilen değişken adlarının buradaki ile birebir aynı olmasına dikkat ediniz.Bu değişken adları proje içerisinde bu şekilde kullanıldı.
-
DynamoDB'ye göndereceğiniz datalarınızın type'ları validasyon işlemi ile sabitlendi (String, Boolean , Number...) Gönderdiğiniz datanın iskeleti şu şekilde olmalıdır.
{ productId:string, stock:number, productName:string, isDiscount:boolean, category:{ categoryId:number, categoryName:string } } -
Yukarıdaki iskelete uygun type'larda veri göndermezseniz kesinlikle veri ekleme işlemi yapamazsınız. Örnek vermek gerekirse isDiscout verisi boolean olmalıdır. Bizim yolladığımız verideki isDiscount = 452145 gibi bir number değerse veri eklenemez. Data'larınız bu validasyon işleminden geçtikten sonra dynamoDB'de sorgu kalitesini kısıtlamamak adına string formatında depolanacaktır.
-
Verilerinizi Postman'den gönderirken JSON formatında olmalıdır.Örneğini aşağıda bulabilirsiniz.
{
"stock":"558",
"productName":"T-shirt",
"isDiscount":"false",
"category":{
"categoryId":"33",
"categoryName":"clothes"
}
}
-
Projenin çalışması için dynamoDB'de tablo oluşturmalısınız. Tabloyu iki şekilde oluşturabilirsiniz.
- Kod ile tablo oluşturmak (Projede kod ile tablo oluşturabileceğiniz bir kod betiği mevcut.)
- Manuel olarak dynamoDB'de tablo oluşturmak
-
NOT-1: Yazdığım kod betiği ile tablo oluşturursanız tablonuzun adı otomatik olarak crud olacağı için projede sorun yaşamazsınız. Kod betiği , tablonuz zaten mevcutsa yeniden oluşturmayacak şekilde tasarlanmıştır.
-
NOT-2: Kod betiği ile tablo oluşturduğunuzda dynamoDB kaynaklı olarak tablonun oluşması zaman alabilmektedir.Tablonun oluştuğunu gördükten sonra işlemlere devam ediniz.
-
NOT-3: Projeyi çalıştırmadan önce npm install yaparak paketleri indireyi unutmayınız.Proje npm start şeklinde başlatılmaktadır.
-
NOT-4: Manuel olarak tablo oluşturacaksanız ismi crud olmalıdır. Proje içerisindeki diğer kodlar bu isme göre tasarlanmıştır.
-
TAVSİYE: Tablo isim uyuşmazlığı sorunundan dolayı kaynaklanabilecek hataların önüne geçmek için kod betiği ile tablo oluşturmanızı tavsiye ederim.
-
localhost:3000/table/crud/create request tipi (POST) -
localhost:3000/table/crud/add request tipi (POST) -
localhost:3000/table/crud request tipi (GET) -
localhost:3000/table/crud/product/:id request tipi (GET)id--> İstenen verinin id'si -
localhost:3000/table/crud/discount request tipi (GET) -
localhost:3000/table/crud/update/:id request tipi (PUT)* id--> Güncellenecek ürünün id'si * Postman'den yollanacak json--> { "stock":"yeni_degeriniz" } -
localhost:3000/table/crud/delete/:id request tipi (DELETE)* id--> Silinecek olan ürünün id'siSQL söz konusu olduğu zaman ilk bahsetmemiz gereken konu ilişkili veritabanlarıdır.Çoğu zaman elimizde birçok veri vardır. Bu verileri tek bir tabloya koyup çok fazla sayıda sütuna sahip olmak yerine birden çok tablo oluşturup bu tabloların ilişkilendirilmesiyle elde edilen yapıya Relational Database (İlişkisel Veritabanı) denir.
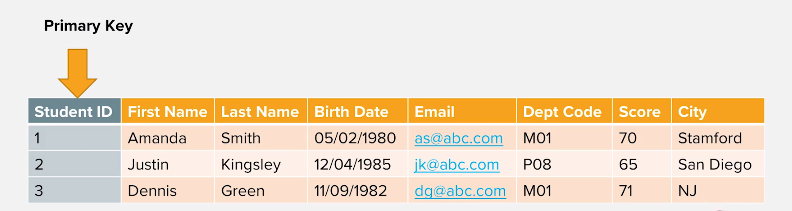
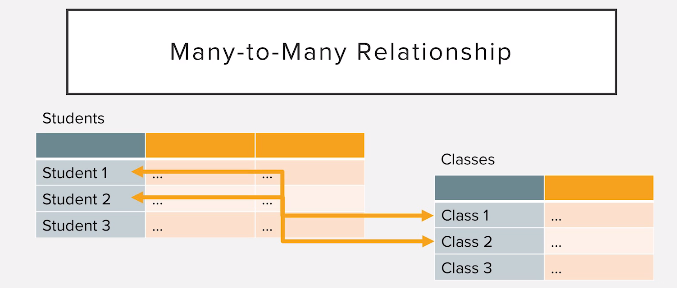
Görüldüğü üzere ilişki kurma şekli görseldeki gibidir. Burada ilişki kurarken primary key'den yararlanırız. Primary key , her satırı benzersiz bir şekilde tanımlamamıza yarar.Bu sayede adete hepsinin bir TC kimlik numarası vardır.
İlişkisel veritabanlarından veri çekerken kullanılan yapıa SQL(Structured Query Language) denir. Burada structured ifadesi aslında SQL ve NoSQL'i birbirinden ayıran temel unsurdur. Bu konuya ileride değineceğiz.
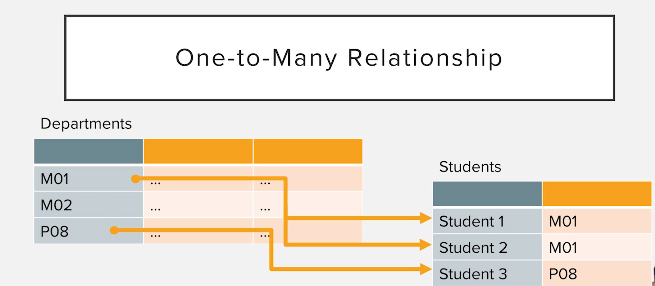
Burada ilişkilendirilen bir tablonun primary key'i diğer tablonun foreign key adı verilen satırları ile ilişkilendirilir. Foreign key olan taraf birden fazla bağlantı kurabildiği için "Many" olarak alandırılır.
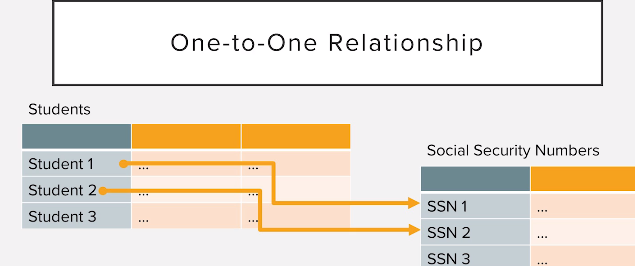
Bu ilişki türünde ise iki tablonun da ilişkili her satırı sadee 1 e 1 olarak bağlanır.
Tahmin edebileceğiniz üzere iki tablo arasında çok a çok ilişki vardır. Pratikte bu ilişki türüne çok rastlanmaz.
NoSQL veritabanları oluşumları gereği ilişkisel olmayan veritabanlarıdır.
SQL'in aksine unstructured bir yapıya sahiptir. SQL veritabanları yapıları gereği dataları excel benzeri katı yapılarda tutarlar.Yani sizin modeliniz en başta name , surname , classname gibi 3 adet yapı içeriyorsa ve SQL de çalışıyorsanız hobbies adında 4. parametreyi veritabanınıza ekleyemezsiniz. NoSQL veritabanlarında ise u yapı oldukça esnektir. Gelen her veri kendi içerisinde bir KEY-VALUE ilişkisine sahip olduğu için belirli bir katı şemaya ihtiyaç duymaz. İşte bu avantajından dolayı NoSQL veritabanları büyük veriler depolamak için mükemmeldir.
Ya hep ya hiç demektir. Bir işlem ya tamamen yürütülebilir ya da hiç yürütülemez.
Bir işlem tamamlandıktan sonra dönen datanın belirli bir schema'ya uyumlu olmasıdır.
Eşzamanlı hareketlerin birbirinen ayrı yürütülebilme özelliğidir.
Veritabanının , beklenmeyen bir hatadan veya kesintiden kurtulabilme yeteneğidir.
İşte SQL veritabanları bu ACID özelliklerine katı bir şekilde bağlıdırlar. Bu durum veritabanı performansını ciddi bir şekilde negatif yönde etkilemektedir. Atomiklik özelliği üzerine biraz dşünürsek bu negatifliği rahatça anlayabiliriz.
NoSQL veritabanları ise bu ACID özelliklerine esnek bir şekilde bağlıdırlar. Bu da performansa direk olarak etki etmektedir.
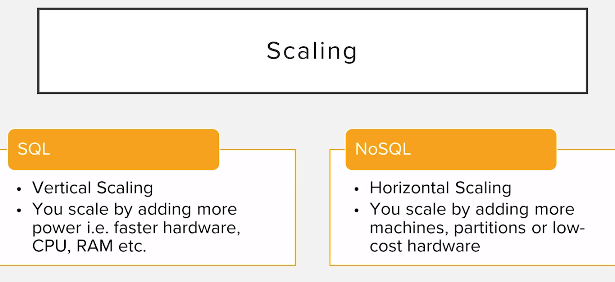
SQL veritabanları dikey ölçeklendirme ile çalışırlar . Bu durum CPU ve RAM'i oldukça yorar. Ancak NoSQL veritabanları yatay ölçeklendirme kullandıkları için bilgisayarımız için daha az zorlayıcıdır.
Sadece sütunlar vardır. Veri depolama ve analiz için kullanılır. Örnek DB'ler Apache , Casandra , Hbase
Her bir veri kendi içerisinde anahtar-değer ilişkisine sahiptir
Bu veritabanı tipinde düğümler mevcuttur. Bu düğümler diğer düğümlerle bağlantılıdır. Tıpkı bir ağaç yapısını andırır
Verileri belge olarak depolamak için tasarlanmıştır. Genellikle depolanma şekli JSON ve XML şeklindedir. JSON daha popülerdir.
DynamoDB veritabanı key-value ve document database tiplerini desteklemektedir.