This project is about tasks for Computer Vision Course in Electronic Information and Communication Department, Huazhong University of Science and Technology, and the teacher is Prof. Xinggang Wang.
| name | usage |
|---|---|
| Proj1 | perceptron for linear classification |
| Proj2 | one layer neural network for classification |
| Proj3 | multi-layer neural network for mnist classification |
| Proj4 | pytorch version for mnist or cifar10 classification |
| Proj5 | pytorch version for single object localization |
| Proj6 | pytorch version for sematic segmentation |
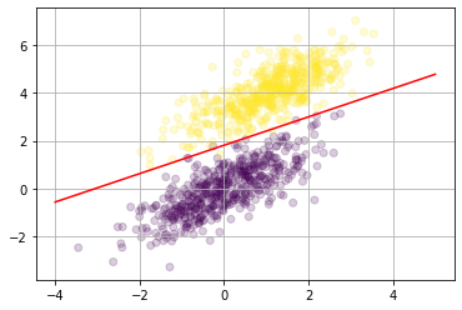
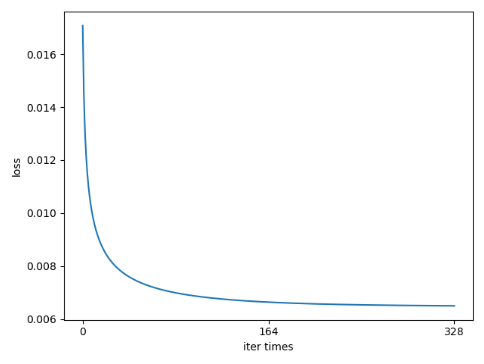
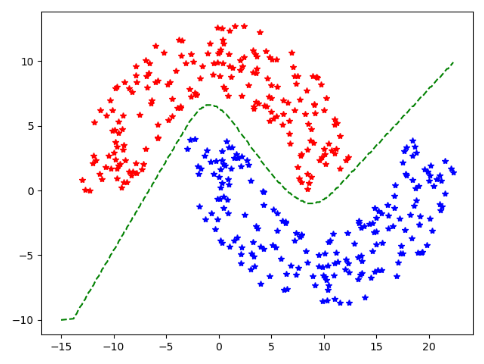
| file | usage |
|---|---|
| function.py | define the activate function such as ReLU, softmax and sigmoid |
| Net.py | define the network structure and forward/backward process |
| mnist.py | how to load data and label from .gz files |
| main.py | batch learning and figure plotting |
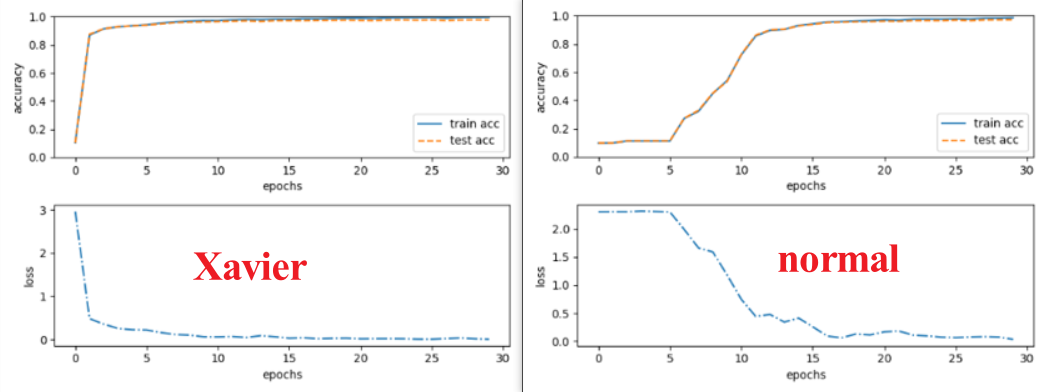
Different activate functions will contribute to different output
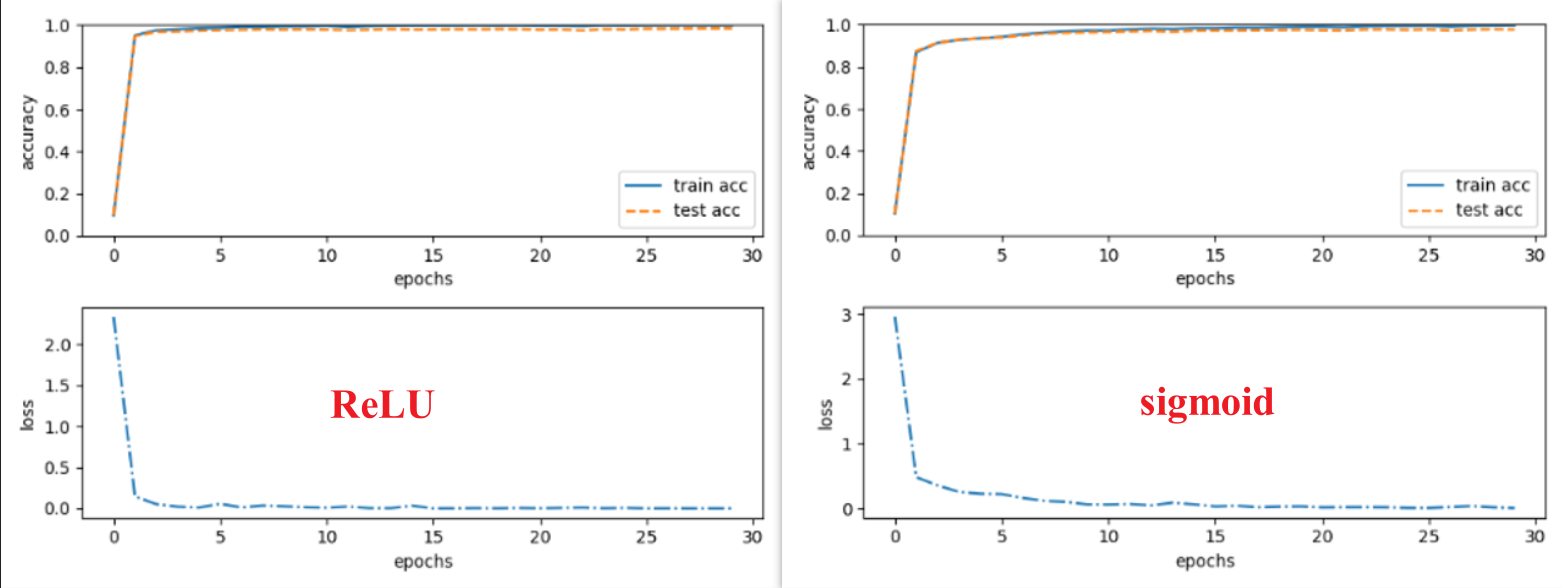
Different init principle will contribute to different output
| file | usage |
|---|---|
| MyNet.py | generate a simply CNN model |
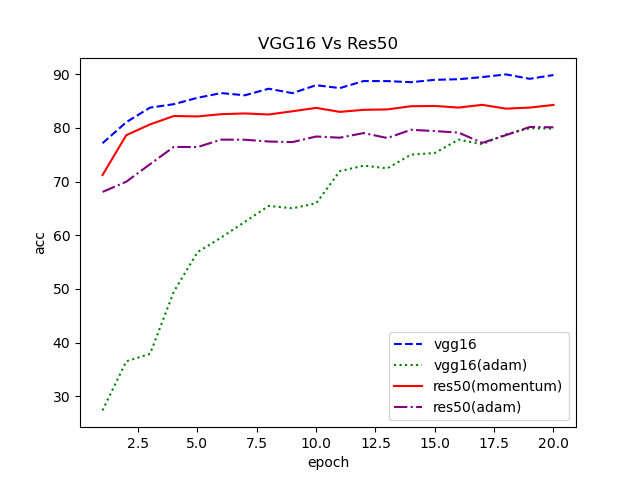
| ResNet.py | transfer learning from Res50 |
| VGG.py | transfer learning from VGG16 |
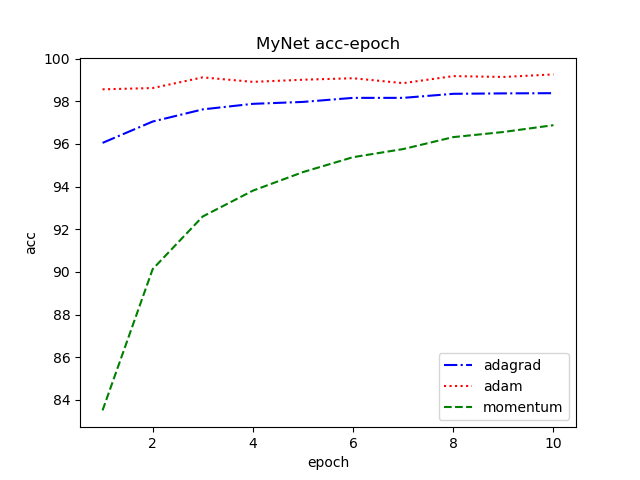
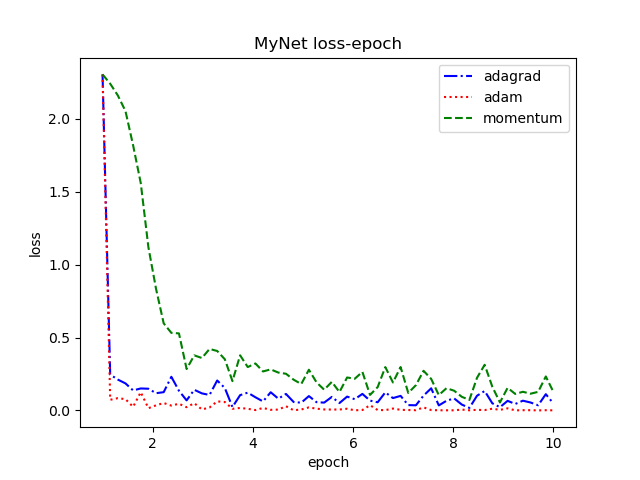
| Plot.py | plot the final results, such as loss and acc |
note: In ./pytorch/models I only store three models, because Res50 and VGG16 models are too huge to store in Github
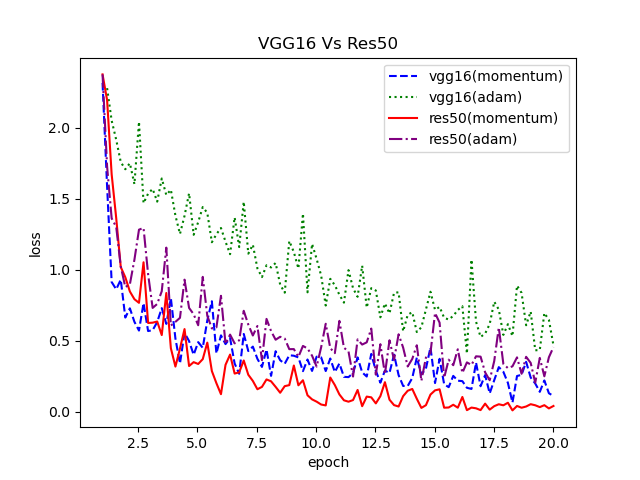
| file | usage |
|---|---|
| Net.py | VGG16 pretrained network + customize |
| VGG_loss_weight.py | main file, use two loss funcs (cross entropy and Smooth L1) |
| VGGConV_xxx.py | using ConV instead fc |
| visualization.py | plot the final results |
| dataloader.py | load data from file as ndarray and tensor |
| tiny_vid.tar | dataset sampled from VID |
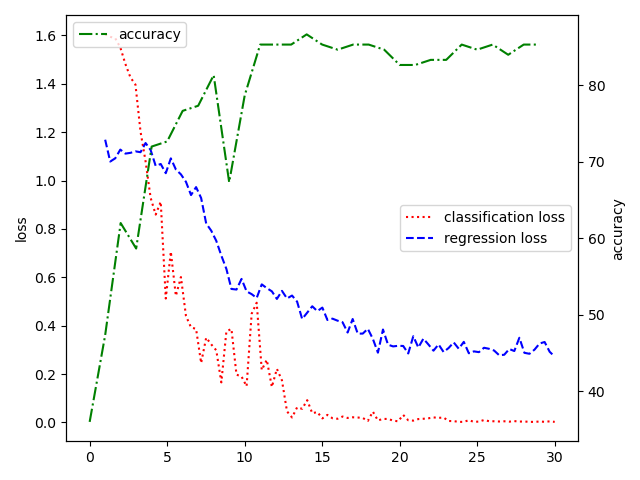
The following figures are "weight=1:1", "weight=1:1e-1", "weight=1:2e-2", "ConV network"
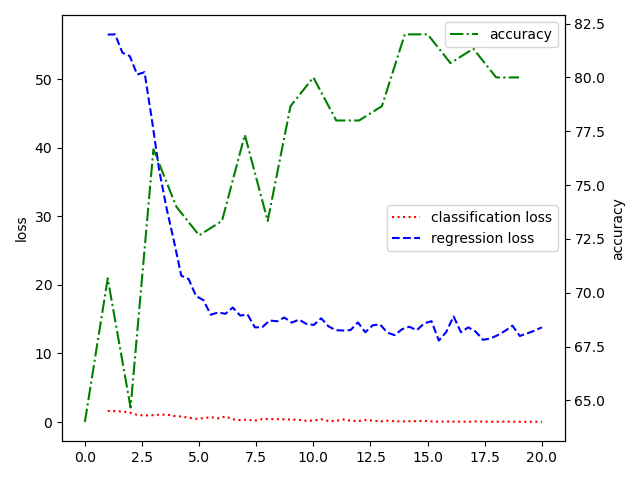
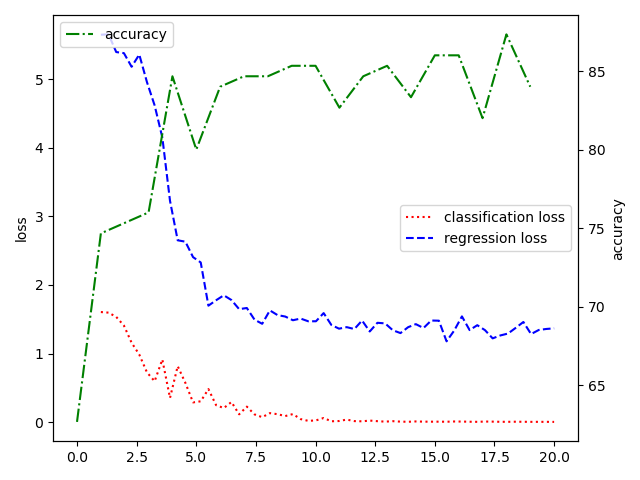
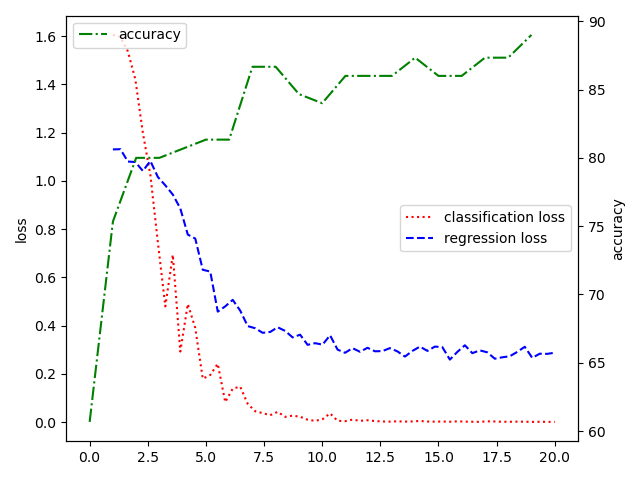


| file | usage |
|---|---|
| TinySeg | dataset sampled from VOC 2012 |
| backbone_8stride.py | ResNet backbone structure |
| eval_seg.py | evaluation code |
| train_seg.py | train code |
| test_seg.py | plot the output imgs |
| pspnet.py | PSP module and network |
| sync_batchnorm | syncronize batchnormal in DeepLab |
| DeepLab.py | define the deeplab v3 network |
| train_seg_deeplab.py | train stage for deeplab net |
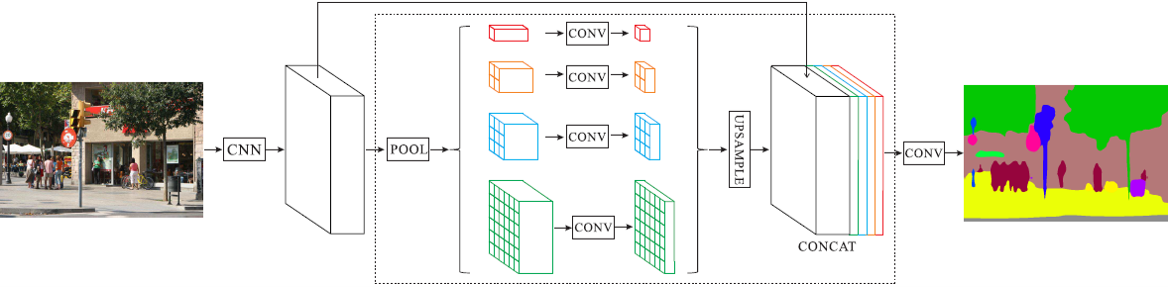
H.Zhao, J.Shi, X.Qi, X.Wang and J.Jia. Pyramid Scene Parsing Network. CVPR2017
- mIoU is about 0.72, while the SOTA of PSPNet in VOC2012 is 0.82


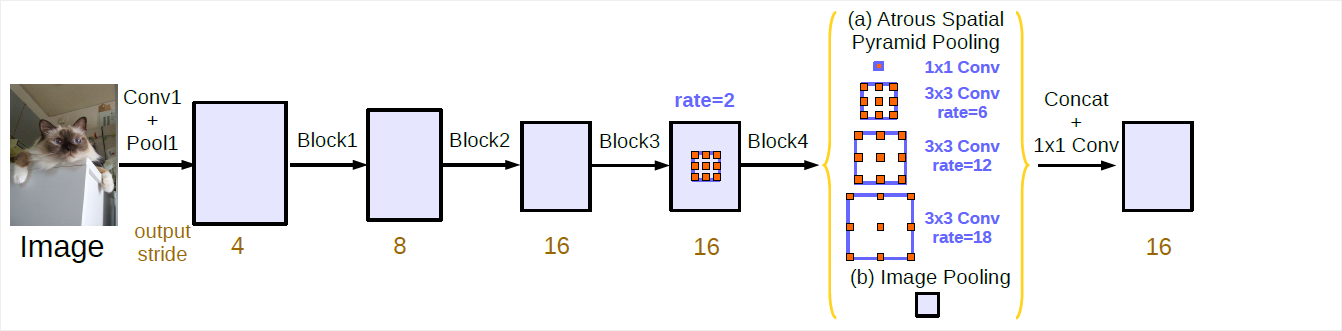
L.Chen, G.Papandreou, F.Schroff, H.Adam. Rethinking Atrous Convolution for Semantic Image Segmentation. arXiv:1706.05587v3
- mIoU is about 0.74