Map Reduce with Python
Hadoop Map Reduce provides the streaming system to execute Map Reduce algorithms using the STDIO so we can execute Map Reduce using Python. a mapper and a reducer script must be provided. The server must have installed the Python runtime.
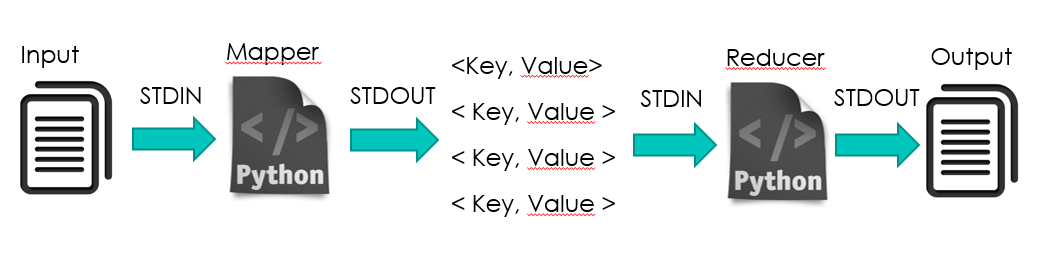
The server has python 2 and python 3 runtimes installed, you can choose between them by declaring the runtime you want to use at the start of the script like so:
#!/usr/bin/env python3.6
will use the python3.6 runtime.
Xrepo does not provide any functionality to manage packages, this must be done by the administrator directly on the Hadoop server.
Python venv is configured on the server, to ease the management of packages. you can create the desired environment and then run scripts against them by also declaring the venv you want to use on the header of the script, as follows:
#!/home/hadoop/xrepo/DateFilter/xr-filter-env/bin/python3
will use the vnev saved on /home/hadoop/xrepo/DateFilter/xr-filter-env
The server has configured the venv with the dateutil=2.8.1 installed, to read and interpret the ISO dated provided in the sampling files. the mapper and reducer files are configured to use this vnev.
To run a streaming job directly on the server you can a script similar to the following one:
mapred streaming \
-file mapper.py -mapper mapper.py \
-file reducer.py -reducer reducer.py \
-input /user/hadoop/input/libros/* -output /user/hadoop/gutenberg-output
You specify the location of the mapper and reducer file, also flag then as files. finally you provide the input and output files location on the HDFS.
both the mapper and reducer are located on the OS and must have execution permissions.