In this project, I have built a pipeline that can be used within a web or mobile app to process real-world, user-supplied images. Given an image of a dog, the algorithm will identify an estimate of the canine’s breed. If supplied an image of a human, the code will identify the resembling dog breed and mention that a human was detected.
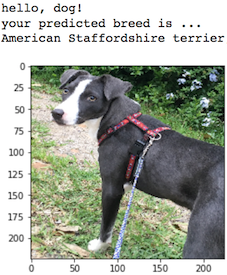
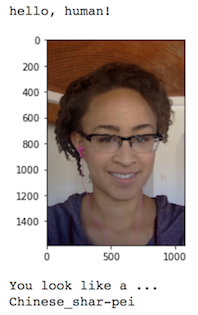
In this project, I have used the pytorch library for help in the implementation of the neural network
-
Clone the repository and navigate to the downloaded folder.
-
Download the dog dataset. Unzip the folder and place it in the repo, at location
path/to/dog-project/dogImages. ThedogImages/folder should contain 133 folders, each corresponding to a different dog breed. -
Download the human dataset. Unzip the folder and place it in the repo, at location
path/to/dog-project/lfw. If you are using a Windows machine, you are encouraged to use 7zip to extract the folder. -
Make sure you have already installed the necessary Python packages according to the README in the program repository.
-
Open a terminal window and navigate to the project folder.
jupyter notebook dog_app.ipynb -
Run each cell. The cells which train the network take a lot of time to process based on the GPU/ CPU installed on the machine.
- Step 0: Import Datasets
- Step 1: Detect Humans
- Step 2: Detect Dogs
- Step 3: Create a CNN to Classify Dog Breeds (from Scratch)
- Step 4: Create a CNN to Classify Dog Breeds (using Transfer Learning)
- Step 5: Write the Algorithm
- Step 6: Test the Algorithm
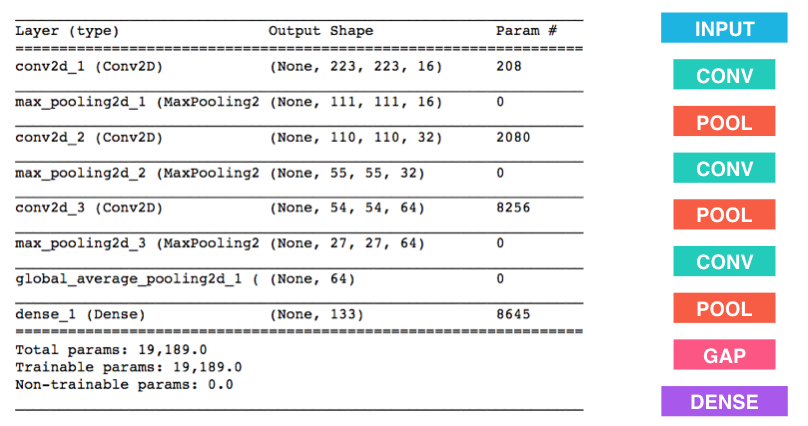
The architechture of this network was achieved by a lot of trial and error. This network contains 4 convulational layers, 4 Max-pooling layers, and 4 fully connected layers. I have implemented the RELU function as the activation function make the output of the first 3 fully connected layers linear. The architecture of the convulational layers is as follows: It receives a tensor with a depth of 3(due to RGB) which adds 61 filters, thus increasing the depth to 64. In a similar manner, the 64 layers are converted to 192, then 256 and finally 512. I have added a padding of 2 units at every convulational step to facilitate that every pixel of the original image is observed and taken into consideration. The kernel/filter size for the first layer is 11X11, 5X5 in the second layer and 3X3 in the 3rd and 4th layer. The stride for the first layer is 4 and for the other 3, the default 1 is used. For the MaxPool layer, the kernel/filter size is 3X3 and the stride is 2, thus, reducing the size of the sides of the image by a factor of 2 at every step. In the fully connected layers, I first flattened the image to a single dimensional tensor of 512 X 4 X 4. I then implemented the 4 linear layers. The first layer gave the output of 5000 nodes, the second one gave an output of 2500 nodes, the third one gave an output of 500 nodes and the fourth and final layer gave an output of 133 nodes which is also the number of dog breeds identified. At every step, I used the dropout function with a probability of removing each datapoint of 25%. I used the RELU function in the first 3 layers and did not use any activation function for the last one.
- Numpy
- Pandas
- cv2
- matplotlib
- tqdm
- glob
- torch
- torchvision.models.models
- PIL.Image
- torchvision.transforms.transforms
- torchvision.datasets
- os
- torch.nn
- torch.nn.Functional
- torch.optim
I believe that the algorithm has a lot of room of improvement. Some of my opinions are:
- The architecture of the network can be tweaked and improved. I chose the Resnet-50 networks as it is one of the best networks which uses an architecture which is very different from the normal neural networks as it is residual in nature. I just replaced the last fully connected layer in order to make the model have 133 classes which wsa required as per the question. However, as there are 50 layers in the network, I can also replace some of the previous fully connected layers which fit better with this network.
- Another potential problem which I found was computing power. The ResNet-50 is a very big network and thus, even training for 1 epoch took a very large amount of time which I why I was forced to train only for 3 epochs. Maybe, if I had better computing power, I could run the network for a few more epochs and check if the loss decreased any further. Similarly, for the network designed from scratch by me could be improved if I had access to better computing power as the I could have tested many more combinationas for the learning rate, epochs, etc.
- Another reason which I believe was obstructing better results was the fact that I was unable to prep the data correctly or as much as required for better training. I think that the images are very messy and there are many factors such as color, light, and other factors which caused discrepancies in the training process. Thus, I believe that extensive methods can be applied to prep the data in such a way that the training goes as smoothly as possible and thus increase the efficiency of the system.