AI와 사람의 대화 데이터로 총 6개의 대분류 감정(분노, 슬픔, 불안, 상처, 당황, 기쁨)안에 60개의 소분류 감정이 있음.
각 감정에 따른 데이터가 고르게 분포 되어 있음.
영화와 음악 추천을 위해 상처 감정은 삭제함
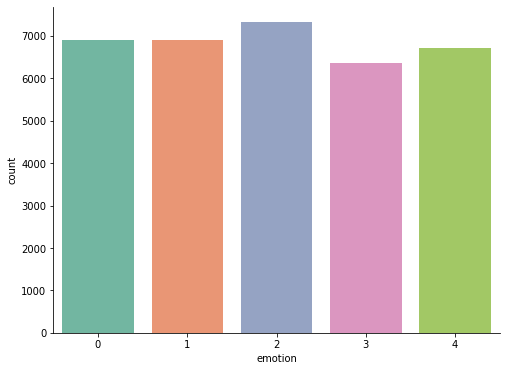
대화 중 인공지능의 대답은 삭제하고 사람의 발화만 저장
사람의 발화 중 문자에 해당하지 않는 부분은 regex로 삭제
이후 감정 숫자 인덱스로 변환
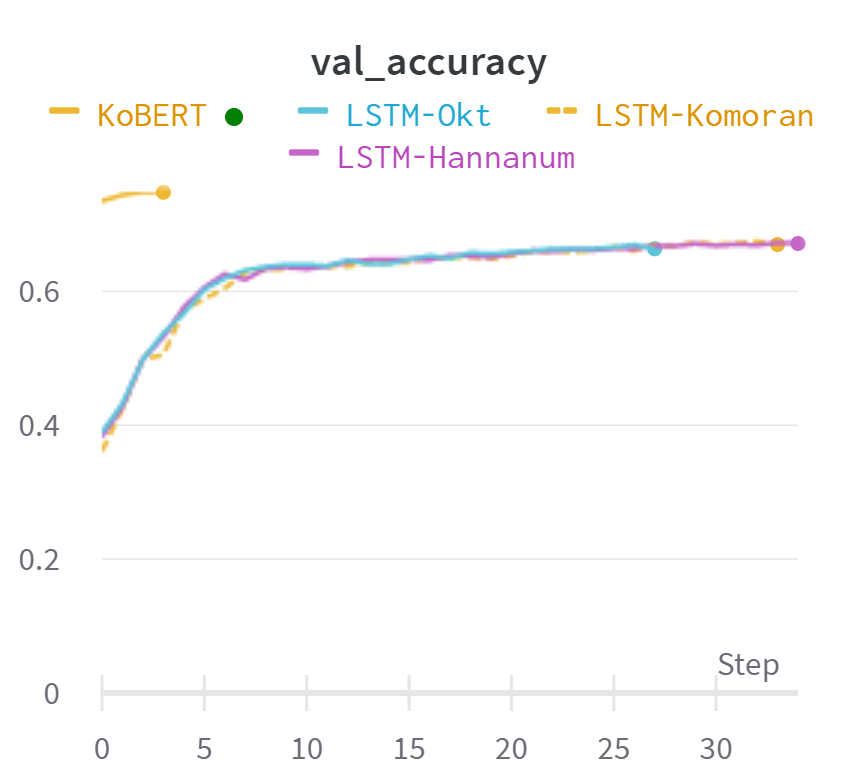
koNLPy의 Okt, Komoran, Hannanum 사용해서 각 성능 비교.
Stopwords 제거는 링크의 데이터를 기반으로 진행.
Stopwords를 형태소 분석을 통해 조사, 어미등을 삭제해줬으나 위 데이터 보다 성능이 떨어져서 사용하지 않음.
Best Valid Accuracy
-
Hannanum :0.6716
-
Komoran :0.6699
-
Okt :0.6636
bert-base-multilingual-cased의 tokenizer와 classfication model사용.
optimizer는 Adam으로 진행.
성능은 나쁘지 않은데 1epoch당 한 시간이 소요돼 사용하지 않았다.
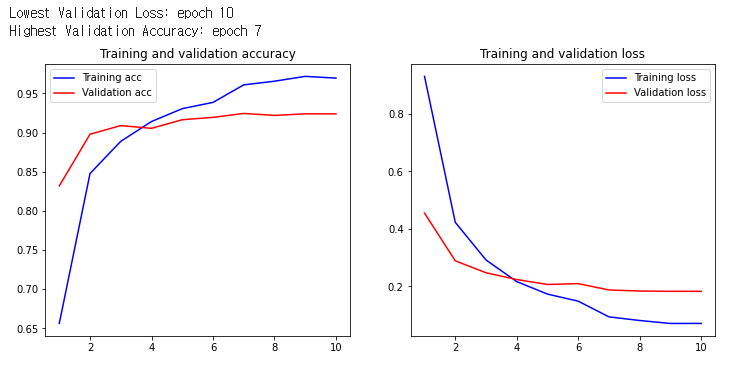
최종 사용 모델.
기본 bert tokenizer 사용.
max-len이 보통 80이하로 끊겨서 80이하로 학습하니 acc는 좋았지만 실 적용에서 체감상 성능이 떨어져 200으로 늘려서 학습시킴. 이 부분에 있어서는 추가 데이터 확보 필요
Best Valid Accuracy : 0.7485
영화와 감정을 연관지을 수 있는 방법을 리뷰에서 찾음.
hugging face에서 제공하는 emotion dataset으로 학습시킨 후 review로 추론해 각 감정당 감정을 느낀 사람이 많은 감정에 해당 영화들을 매치
-
영화 리뷰, 영화 아이디로 이루어진 sent table
-
감독, 배우 아이디 crew table
-
감독, 배우의 이름이 매치되는 name table
-
영화 아이디, 영화 제목, 영화 개봉년도로 구성된 title table
sent table로 추론 후 모든 table을 id concat해 영화 제목, 감독을 받아오며 작품의 연도가 90년도 이상의 영화만 받아오도록 처리.
Hugging face에 공개된 DistilBERT 사용
https://sites.tufts.edu/eeseniordesignhandbook/2015/music-mood-classification/를 기반으로 분류
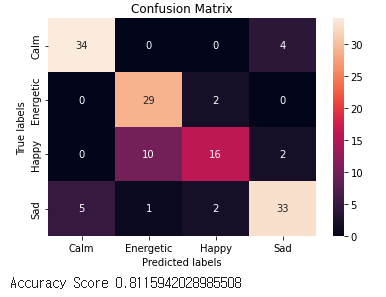
Spotify에서 제공하는 여러 음악 요소를 가지고 Happy, Sad, Calm의 감정을 구분 하는 학습 진행
학습 데이터는 https://github.com/cristobalvch/Spotify-Machine-Learning의 data_moods.csv로 진행했으며 추론은 spotify의 한국 playlist uri를 가져와 진행했다.
Keras에서 제공하는 classifier 사용.
platform : AWS EC2
S3에 학습된 모델 파일 올려서 AWS cli활용해 다운로드 후 inference.
프리티어인 micro사용시 모델 로딩부터 프로세스가 죽어버리는 관계로 t2.Large 사용.
감정의 공유가 목적인 만큼 유저의 대략적 정보(나이대, 성별, 지역 등)과 감정을 매치해 다른 유저 중 나와 동일한 감정을 느끼는 유저들이 이용한 콘텐츠를 추천할 수 있어야 한다.
따라서 현재 콘텐츠에서 feedback을 받아 데이터를 수집한 다음 완전한 추천시스템 모델로 바꿔야한다.
또한, BERT의 경우 무거운 편이라 추론시 시간이 걸리므로 feature engineering과 데이터 추가 수집을 통해 최대한 성능을 끌어올리며 가벼운 ML모델로 교체해야한다.