一个简单易用的音频转文字工具,支持多种语音识别方案。
{kind=link}
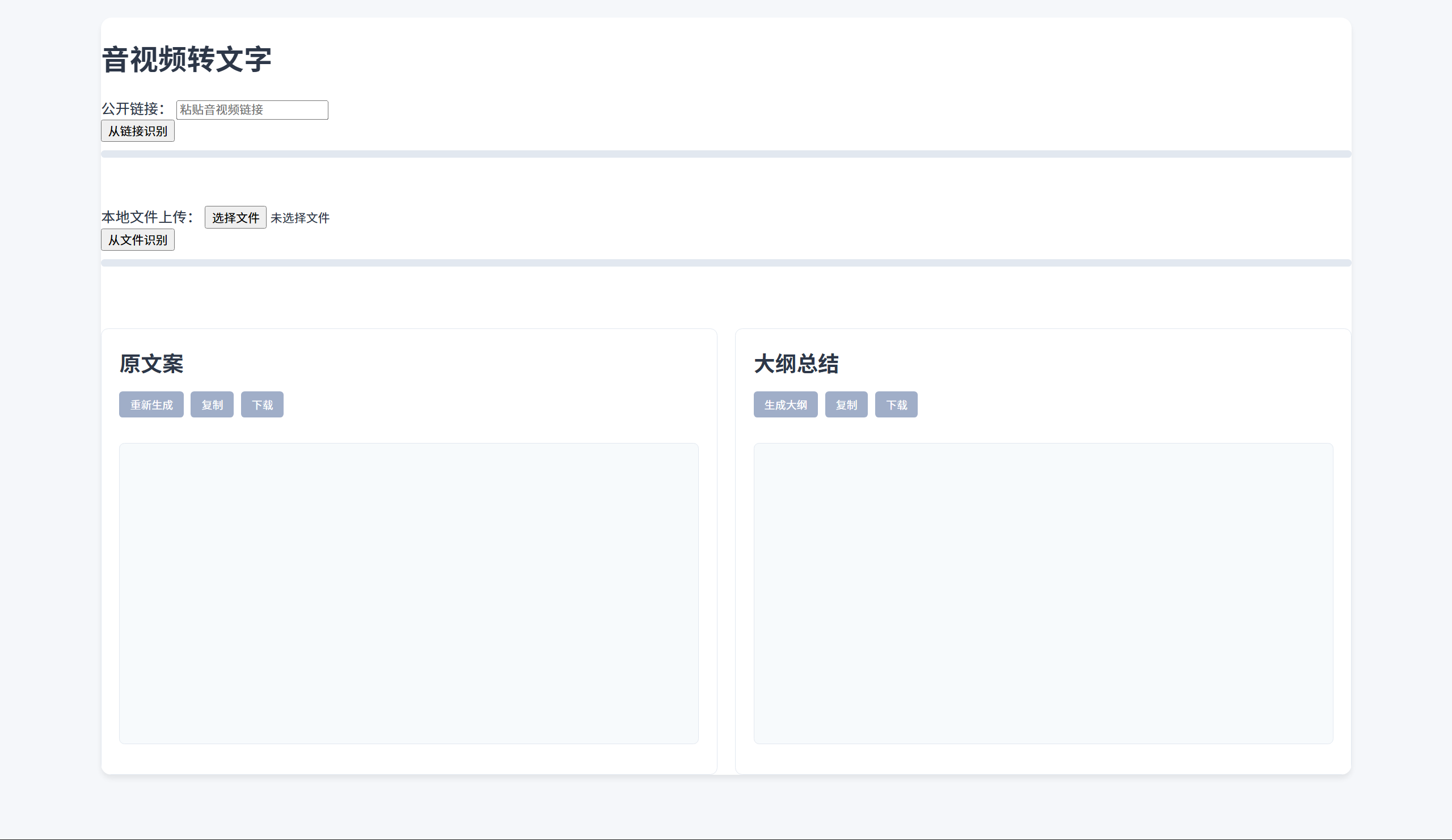
主要功能区域:
- 顶部输入区:支持输入公开链接(YouTube、B站等)或上传本地音视频文件
- 左侧原文案区:显示经过LLM优化的结构化文本内容,支持复制和下载功能
- 右侧大纲总结区:自动生成的文本大纲,支持一键生成、复制和下载
界面设计注重简洁易用,无需复杂配置即可快速上手。
🎯 核心功能
- 🎵 自动下载公开链接中的音频/视频(支持YouTube、B站等)
- 📝 智能语音识别(ASR),支持多种方案
- ✨ AI文本优化,自动分段和提升可读性
- 📋 智能大纲生成,提取关键信息和结构化要点
- 🌐 简洁的Web界面,无需复杂配置
⚡ 支持的ASR方案
- OpenAI Whisper - 云端识别,准确率高
- 国产云ASR - 国内优化,价格实惠
- 本地模型 - 离线使用,隐私安全
- Python 3.9 或更高版本
- 至少 4GB 可用内存(本地ASR需要更多)
- 稳定的网络连接(使用云服务时)
-
克隆项目
git clone https://github.com/your-username/podcast-to-text.git cd podcast-to-text -
创建虚拟环境并安装依赖
python -m venv .venv # Windows .venv\Scripts\activate # macOS/Linux source .venv/bin/activate pip install -r requirements.txt
-
配置环境变量
cp .env.example # 编辑 .env 文件,填入必要的API密钥 -
启动服务
python server.py
-
访问应用 打开浏览器访问 http://127.0.0.1:8000
- 准确率: 英文>95%,中文>90%
- 处理速度: 1小时音频约3-5分钟
- 优点: 准确率高,支持多语言,无需本地硬件
- 缺点: 需要OpenAI API密钥,网络要求稳定
- 成本: 约$0.006/分钟(1小时约$0.36)
国内云服务商提供的中文语音识别服务,适合中文场景: 支持的服务商(需自行注册和配置):
- 阿里云智能语音交互
- 腾讯云语音识别
- 百度智能云语音
- 讯飞开放平台
配置方法:
- 注册对应服务商账号并开通语音识别服务
- 获取API密钥和相关配置信息
- 在
.env文件中设置对应的环境变量
注意事项:
- 各服务商的SDK和鉴权方式不同
- 价格和免费额度各有差异
- 中文识别准确率普遍较好
提示:默认配置不变。只有当你设置了
ASR_PROVIDER=faster_whisper或ASR_PROVIDER=aliyun_nls时,才会走对应ASR逻辑。
| 模型大小 | 内存需求 | 显存需求 | 准确率 | 1小时处理时间 |
|---|---|---|---|---|
| tiny | 1GB | 无 | 70% | 5分钟 |
| base | 2GB | 无 | 78% | 8分钟 |
| small | 4GB | 无 | 85% | 15分钟 |
| medium | 8GB | 4GB | 90% | 30分钟 |
| large | 16GB | 8GB | 95% | 60分钟 |
| 本地模型缺点: |
- 首次下载模型文件较大(small模型约500MB)
- 处理速度慢,特别是大文件
- 需要较好的CPU/内存配置
- 准确率通常低于云服务
本项目默认使用 OpenAI。若在国内访问受限,可改用“OpenAI兼容”的服务,只需在 .env 设置:
LLM_API_KEY=你的其他服务密钥
LLM_BASE_URL=该服务的OpenAI兼容API地址
LLM_MODEL=该服务对应的模型名称
示例(任选其一,按服务商文档填写):
- DeepSeek:
LLM_BASE_URL=https://api.deepseek.comLLM_MODEL=deepseek-chat
- OpenRouter:
LLM_BASE_URL=https://openrouter.ai/api/v1LLM_MODEL=openrouter/auto
- 硅基流动(SiliconFlow):
LLM_BASE_URL=https://api.siliconflow.cn/v1LLM_MODEL=deepseek-ai/DeepSeek-V3
- 本地 Ollama:
LLM_BASE_URL=http://127.0.0.1:11434/v1LLM_MODEL=llama3.1:8b
| 变量名 | 说明 | 默认值 | 是否必需 |
|---|---|---|---|
OPENAI_API_KEY |
OpenAI API密钥 | 空 | 使用OpenAI Whisper时必需 |
LLM_API_KEY |
文本优化LLM密钥 | 空 | 可选,可与OPENAI_API_KEY共用 |
LLM_BASE_URL |
OpenAI兼容API地址 | 空 | 使用第三方LLM服务时设置 |
LLM_MODEL |
LLM模型名称 | gpt-4o-mini | 可选 |
ASR_PROVIDER |
ASR提供商选择 | openai | 可选 |
ASR_MODEL |
ASR模型选择 | whisper-1 | 可选 |
# .env 文件内容
OPENAI_API_KEY=sk-your-openai-key-here
ASR_PROVIDER=openai
ASR_MODEL=whisper-1# .env 文件内容
# 以阿里云NLS为例,其他服务商请参考各自文档
ASR_PROVIDER=aliyun_nls
ALIYUN_ACCESS_KEY_ID=your-access-key
ALIYUN_ACCESS_KEY_SECRET=your-secret-key
ALIYUN_NLS_APP_KEY=your-app-key
OSS_BUCKET=your-oss-bucket
OSS_ENDPOINT=https://oss-cn-shanghai.aliyuncs.com# .env 文件内容
ASR_PROVIDER=faster_whisper
ASR_MODEL=small
# 可选:指定本地模型目录
ASR_LOCAL_DIR=C:\models\faster-whisper-smallA: 你可以:
- 注册OpenAI账号获取API密钥(推荐)
- 使用国产云ASR服务(适合中文场景)
- 使用本地模型(无需密钥,但需要较好硬件)
A:
- 检查网络连接是否稳定
- 确认链接是否为公开内容
- 尝试其他平台链接
- 检查是否被防火墙阻止
A:
- 使用更小的模型(tiny/base)
- 升级硬件配置(CPU/内存)
- 考虑使用云服务(OpenAI/国产云ASR)
- 减少同时处理的任务数量
A:
- 检查音频质量是否清晰
- 尝试使用更大的模型
- 考虑使用云服务获得更高准确率
- 确保音频语言与模型匹配
A:
- 设置音频分块参数:
ASR_CHUNK_MIN=10(每10分钟切分) - 确保有足够内存
- 考虑使用云服务处理大文件
- 音频下载: 使用yt-dlp从公开平台下载音频
- 语音识别: 将音频转换为原始文本(ASR)
- 文本优化: 使用LLM对原始文本进行分段和优化
- 大纲生成: 自动分析文本内容,生成结构化大纲
欢迎提交Issue和Pull Request来改进这个项目!
git clone https://github.com/your-username/podcast-to-text.git
cd podcast-to-text
python -m venv .venv
source .venv/bin/activate # Linux/Mac
# 或 .venv\Scripts\activate # Windows
pip install -r requirements.txt- 使用清晰的提交信息
- 添加必要的测试
- 更新相关文档
本项目采用MIT许可证 - 详见 LICENSE 文件
- OpenAI Whisper - 优秀的语音识别模型
- yt-dlp - 强大的媒体下载工具
- Flask - 轻量级Web框架
如有问题或建议,欢迎通过以下方式联系:
- 提交GitHub Issue
⭐ 如果这个项目对你有帮助,请给个Star支持一下!