This is an implementation of Huffman decoding with assembly langauges
허프만 디코딩을 위해 먼저 ranktable을 완성하고 register의 용도를 고정한 이후 들어오는 input을 순차적으로 읽어옵니다. Input을 순차적으로 읽어오는 알고리즘을 구현하고 output을 하나씩 저장한 이후 이를 *outp에 저장하는 절차로 진행했습니다.
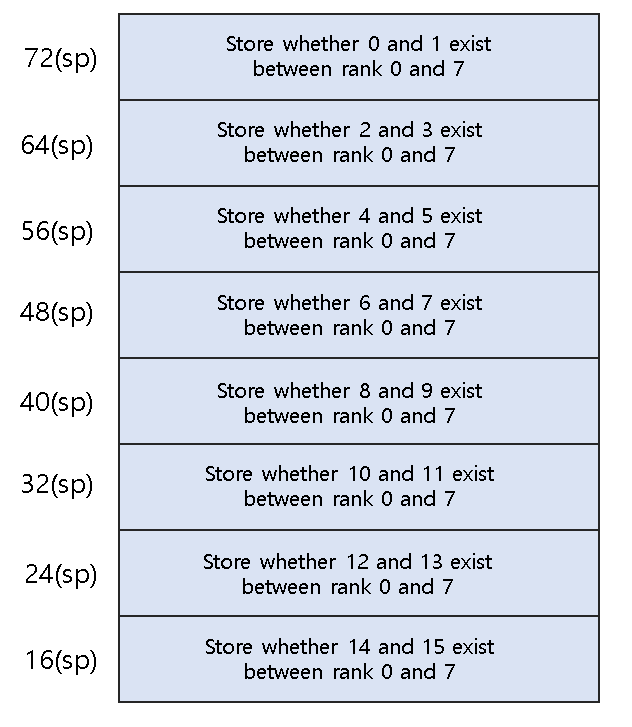
가장 먼저 a0, a1, a2, a3, a4, a5 register 를 자유롭게 사용하기 위해서 인자로 들어오는 a0, a1, a2, a3 를 스택에 저장시켜 놓았습니다. 다음은 rank table 을 만들어야 하는데 0부터 7 순위가 아닌 8 -15 순위인 숫자를 찾기 위해서 0 7 순위에 있는 숫자가 등장하면 스택의 정해진 위치에 1 을 추가하는 형식으로 구현을 했습니다. 72(sp)에는 0 과 1 의 숫자 64(sp) 에는 2와 3의 숫자, 56(sp) 에는 4 와 5 의 숫자 … 16(sp) 에는 14 와 15 의 숫자의 자리의 횟수가 들어가게 했습니다. 즉 72(sp)의 숫자가 0x11이라면 0 - 7 rank에 0과 1이 모두 등장하는 것이고 0x10 이라면 0만 등장하는 것이며 0x01 이라면 1 만 등장하는 경우입니다. 이렇게 0 - 7 ranktable 에 사용되는 숫자들을 다 1 로 표시한 이후 스택의 지정된 부분을 돌면서 0 인 부분을 찾 아 8 - 15 인 ranktable 을 완성하게 됩니다 각각의 스택을 돌면서 지정된 스택의 숫자가 0 x 11, 0 x 10, 0 x 01 인 경우로 나누어 a 1 register 에 rank 에 8~15 인 숫자들을 적어주게 됩니다. 이후 완성된 8-15 rank 의 숫자들을 4(sp) 스택에 store 해줍니다. 0-7 rank의 숫자들은 0(sp) 에 저장해두었습니다.
4 byte는 ranktable로 무조건 들어오게 되는 것이고 이후 들어오는 byte가 4byte를 넘는지 판단하는 절차를 거칩니다. 4byte를 넘는다면 우선 첫 byte의 길이는 padding bit을 제외하면 28bit가 됩니다. 이 경우 코드부분에서 keepgoing이라는 부분으로 구현하였습니다. 하지만 4byte를 넘지 않는다면 paddingbit을 고려하여 length가 달라질 수 있기 때문에 처음에 inbyte의 길이를 경우의 수를 나누어 계산하였습니다.
이제부터 특정 register를 특정 용도로만 사용하고 특정 스택의 위치를 특정 용도로만 사용하기로 했습니다.
- a1: a1의 register는 output을 저장하는 용도로 사용하는데 32bit가 채워지게 되면 이를 지정된 *outp 에 저장하고 a1은 다시 0으로 초기화를 시킵니다.
- a0: a0 register는 지금 현재 상황을 keep track하기 위해서 사용합니다. a0 register의 마지막 4 bit은 현재 output이 store된 것이 몇개인지 추적합니다. 만약 마지막 4bit이 5라면 output이 5X4=20 bit만큼 저장되어있는것입니다. 그러므로 마지막 4bit이 8이 되면 그것을 outp 특정 장소에 저장하고 초기화하는 작업이 필요합니다.
- a5 register는 현재 bit의 상황을 저장합니다.
- a0의 upper bits는 a5 register의 bit가 몇 개 남았는가를 기록합니다.
- a5의 길이는 32bit으로 시작하여 bit를 3개, 4개, 5개씩 읽음에 따라 길이가 줄어들게 됩니다. 만약 31만큼 a5를 shift했을 때 0이면 threebit으로 가서 읽고, 30만큼 shift했을 때 2이면 fourbit으로 가서 읽고, 3이면 fivebit으로 가서 읽게 됩니다.
- 112(sp)는 현재 남은 inbytes를 저장하는데 만약 다음 input이 a5에 모두 올라갔을때를 기준으로 -4씩 감소하여 새롭게 store해줍니다.
- 28(sp)의 경우 다음 들어와야 할 input을 저장하는 용도로 사용합니다.
- 20(sp)는 다음 input의 길이를 저장하는 용도로 사용합니다.
Threebit일 경우 a0를 48(163)만큼 감소시키고 fourbit의 경우 164 만큼, fivebit의 경우 16*5만큼 감소시키는데 감소함에 따라 a0의 upperbit이 음수가 되게 되면 다음 input을 load해와야 하는 상황임으로 next의 상황으로 가게 됩니다. 하지만 더 이상 읽어올 bit이 없을경우에는 input의 마지막 부분이라는 뜻이기 때문에 paddingbit 부분으로 가서 추가적인 조정을 해줍니다. 다음 input을 읽어오는 과정이 복잡한데 만약 20(sp) 부분이 0이라면 새로운 input stream을 읽어와야 한다는 뜻이므로 loadnext로 가서 새로운 input stream을 읽습니다. 하지만 20(sp) 부분이 0이 아니라면 이미 들어올 input stream이 있다는 뜻이므로 새로운 것을 load하지 않습니다. 그래서 nottotal 부분으로 가는데 여기서도 경우가 나뉘게 됩니다. a5에 새로운 byte를 load한 이후에도 저장되어있는 input stream이 다 들어가지 않은 경우가 있고 모두 들어가는 경우가 있는데 모두 들어가는 경우에는 ifcase로 가서 특별하게 처리를 해줍니다. 3 bit, 4 bit, 5 bit씩 읽어 각각에 해당하는 ranktable과 매치시켜 output stream에 하나씩 저장을 해줍니다. 32bit가 채워지게 되면 outbytes의 수도 4씩 감소시킵니다. 이는 코딩된 outbytes가 정해진 outbytes의 수를 넘을 수 없기 때문에 만약 outbytes의 수가 0보다 작아지게 된다면 store하는 것을 멈추고 return을 해주어야 하기 때문입니다.