Add fingerprint support #7
Conversation
89b67df to
b2fdbb6
Compare
|
@enkessler thanks for fixing this upstream, I just rebased are you open to merging the remainder of the changes in ? |
|
@alexanderjeurissen Admittedly, I've looked at this PR the least because it has actually significant enhancements and I've been running off to do the other quick/intriguing stuff instead (not that this stuff isn't still useful). My mind may or may not be overwhelmed by other things this week but I will get back to this in the near future. |
|
Out of curiosity, what is the main benefit of having a fingerprint method over just the |
For two reasons, one is performance, the other is additional use-cases that a fingerprint enables. PerformanceString comparison is way more performant than object comparison. I created a integration spec with This performance difference is even more significant when taking into account that with the same spec as above, with
Additional use-casesfingerprint strings allow for easier and faster lookup when traversing a directory, feature_file, or feature. Fingerprints are strings and thus can be stored in a hash, allowing for |
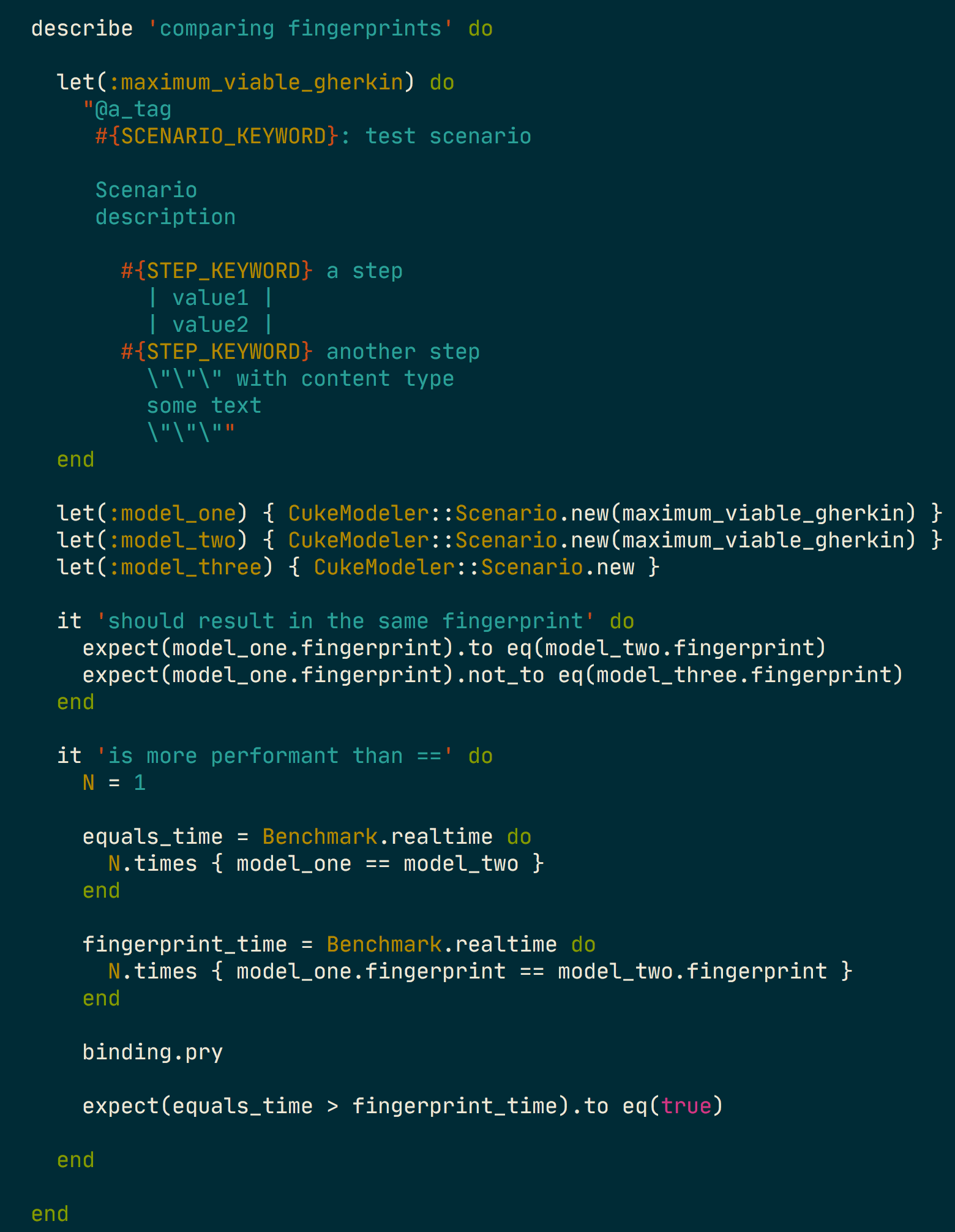


|
It might be interesting to refactor the |
|
@enkessler does the above answer your question ? |
|
So Regarding the calculation of the hash value, it would certainly be easy on the development side to just base it off of That reminds me, I still need to get around to having the string form of |
|
@alexanderjeurissen poke In summary: I'm okay with this as long as the fingerprint is based on the various attributes of the model instead of being based on the string output. |
Summary of changes
This PR adds a new methods to the
CukeModeler::Modelclass:This methods generate a
Digest::MD5hex digest of theto_sreturn value of a given model.A block can be provided to control what attribute or value is used to generate the fingerprint
Use-cases / context
The use-case for this new method is easy comparison between models.
For instance, using the
fingerprintmethod one can confirm if twoScenariosare exactly the same or if two scenarios use the exact same steps.Below is an example
cuke_linterthat could be build with these changes merged in.