A service for entity linking of properties
- Make sure there is an available version of python specified in
pyproject.toml, for example installed using pyenv. - Install
uv:curl -LsSf https://astral.sh/uv/install.sh | sh - Run
uv sync --all-groupsto create a local environment with project dependencies specified inuv.lock - Add a spacy language model
uv run spacy download en_core_web_trf - Set up
pre-commithooks:uv run pre-commit install. - To run
pre-commitindependently fromgit commit, runuv run pre-commit run --all-files - To run tests run
pytest test
NB.
- To run python scripts prefix the command with
uv run, e.g.uv run python script.py - To git commit also
uv runprefix, e.g.uv run git commit -m "first commit"to make surepre-commithooks are used from the correct python environement.
run/preprocessing/extract_properties_rorun/preprocessing/extract_properties_go
Uniformize and trim data incoming from different sources
run/preprocessing/merge_properties
Ground truth dataset is stored in data/ground_truth, so run the following to obtain the accuracy of the model in ./reports
python run/testing/run_pel_test.py --text-path ./data/ground_truth/sample.0.gt.json --model-type biobert-stsb --layers-spec sent --extra-context
"Train" a model on a corpus
uv run python run/save_model.py
poetry run python run/serve
- Build image:
docker buildx build -t gg/pelinker:<current_version> --ssh default=$SSH_AUTH_SOCK . 2>&1 | tee build.log - Run container:
docker run --name pelinker --env THR_SCORE=0.5 gg/pelinker:latest
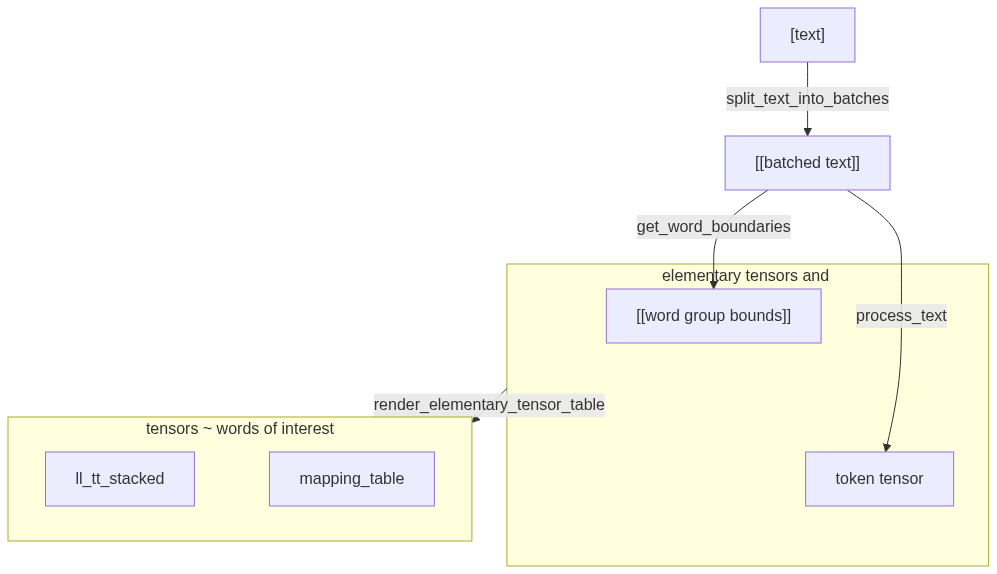
flowchart TD
A["[text]"] -->|"split_text_into_batches"| B["[[batched text]]"]
subgraph S1["elementary tensors and word bounds"]
direction LR
C ~~~ D
end
B -->|"get_word_boundaries"| C["[[word group bounds]]"]
B -->|"process_text"| D["token tensor"]
subgraph S2["tensors ~ words of interest"]
direction LR
E["ll_tt_stacked"] ~~~ F["mapping_table"]
end
S1 -->|"render_elementary_tensor_table"| S2
An essential part of analysis is to identify patterns in text and study their embeddings vectors.
To run pattern matching over different models and patterns, and plot them to figs folder, where the texts are taken from a csv file with a column named abstract:
cd run
./test.pat.align.sh ./test.pat.align.sh --pattern pat_a --pattern pat_b --plot-path figs --input-path data/test/sample.csv.gz