forked from barryclark/jekyll-now
-
Notifications
You must be signed in to change notification settings - Fork 0
Oslo moea parsing #5
New issue
Have a question about this project? Sign up for a free GitHub account to open an issue and contact its maintainers and the community.
By clicking “Sign up for GitHub”, you agree to our terms of service and privacy statement. We’ll occasionally send you account related emails.
Already on GitHub? Sign in to your account
Open
oslo0322
wants to merge
2
commits into
master
Choose a base branch
from
oslo_moea_parsing
base: master
Could not load branches
Branch not found: {{ refName }}
Loading
Could not load tags
Nothing to show
Loading
Are you sure you want to change the base?
Some commits from the old base branch may be removed from the timeline,
and old review comments may become outdated.
Open
Changes from all commits
Commits
Show all changes
2 commits
Select commit
Hold shift + click to select a range
File filter
Filter by extension
Conversations
Failed to load comments.
Loading
Jump to
Jump to file
Failed to load files.
Loading
Diff view
Diff view
There are no files selected for viewing
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,77 @@ | ||
| --- | ||
| layout: post | ||
| title: 如何使用 Machine-Learning 去處理一些非規則性的資料 | ||
| author: oslo0322 | ||
| --- | ||
|
|
||
| 在 iCHEF,我們會利用政府公開的資料做一些處理並加以利用,經濟部商業司(Ministry of Economic Affairs,R.O.C.) 以下簡稱 `MOEA` 就是其中一個我們會利用的資料。 | ||
|
|
||
| MOEA 會在每個月10號釋出一些公司或者商業的登記資料,這些資料的格式是 `PDF`,內容則有點像是 `EXCEL`的樣式。 | ||
|
|
||
| ## 分析資料 | ||
|
|
||
| ### 工具 | ||
| 所謂工欲善其事,必先利其器,分析之前要先準備好工具 | ||
|
|
||
| 而處理的工具,我們使用的是 `python`,下面列出最主要的工具 | ||
|
|
||
| * [PDFMiner](https://github.com/euske/pdfminer) 處理 PDF 的工具 | ||
| * [scikit-learn](http://scikit-learn.org/stable/) ML工具 | ||
| * pandas/numpy/scipy python 數據分析的好用工具 | ||
|
|
||
| ### 思考 | ||
| 謀定而後動,在開始處理資料之前,我們先來看看我們要處理的資料是什麼樣子 | ||
|
|
||
|  | ||
| 上圖是 PDF 內其中一頁,可以看到大致上跟 `EXCEL` 一樣,除了最後面`營業項目說明`除外,而通常我們的觀念會想要最後一欄,歸類在同一行的營業人,也就是下圖的概念。 | ||
|  | ||
|
|
||
| ### 工具特性 | ||
| PDFMiner 是將PDF的內容變成座標形式回傳的,以下圖為例 | ||
|
|
||
| 『1』一個字就有一組四個`(x, y)`座標,座標是由左下角開始,x往右變大,y往上變大 | ||
|  | ||
|
|
||
| 字或者詞的判斷則是由下面的圖來解釋如何運作的 | ||
|  | ||
|
|
||
| * M 表示兩個『字』之間的水平距離,如果大於某個值會判斷成兩個詞 | ||
| * W 表示兩個『詞』之間的水平距離,如果大於某個值會判斷成兩個詞 | ||
| * L 表示兩個『詞』之間的垂直距離,如果大於某個值會判斷成兩個斷行 | ||
|
|
||
| ### 資料特性 | ||
|  | ||
| 上圖可以很清楚地知道,欄位其實在某些地方有些不一樣(藍色線標明的地方),像是名字因為兩個字置中而導致起始位置跟三個字的地方有些不一樣,大部分欄位都是靠左對齊,資本額的地方卻是靠右對齊,造成起始座標很難歸納出一個範圍。 | ||
|
|
||
|
|
||
| 在分行的地方相對欄位來說,則是比較簡單的,可以藉由字詞 `y` 的高度來判斷多少範圍內是屬於同一個營業人的情況 | ||
|
|
||
| 例如: | ||
|
|
||
| * y的高度 (0, 484] 屬於最下面序號『9』的營業人 | ||
| * y的高度 (484, 515] 屬於最下面序號『8』的營業人 | ||
|
|
||
| ## 解決問題 | ||
| 上述提到一個問題,欄位因為起始點不同,所以很難歸納出真正的範圍,這時候機器學習就派上用場了 | ||
|
|
||
| 我們要解決的是分群的問題,分群常用的方法就屬於 `KNN` 了,`KNN` 是一種非監督式的機器學習演算法,簡單來說就是物以類聚的概念,我們利用未知座標 X 最鄰近的 N 個點來判斷 X 是屬於哪一個群組,以下圖為例 | ||
| 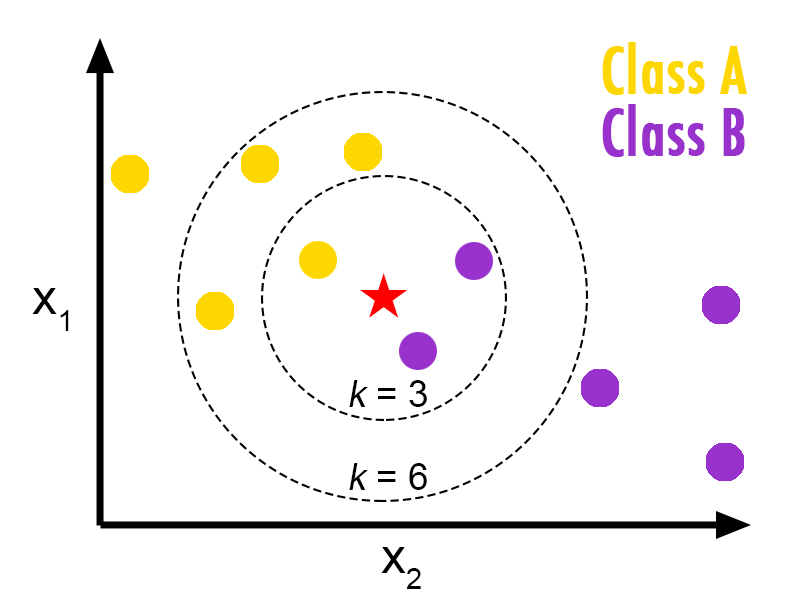 | ||
| 我們已經知道有『黃色』以及『紫色』兩組顏色,今天如果想要判斷『紅色』星星是屬於哪一個群組,KNN 中的 N 值,設定的不一樣,則會帶來不一樣的結果 | ||
|
|
||
| > 如果 N 等於 3,半徑 3 的範圍內有兩個紫色一個黃色,那麼程式就會判斷有33.333%的機率是黃色,66.667%的機率是紫色 | ||
| > | ||
| > 如果 N 等於 6,半徑 6 的範圍內有四個紫色兩個黃色,那麼程式就會判斷有66.667%的機率是黃色,33.333%的機率是紫色 | ||
|
|
||
| 我們利用這種物以類聚的概念來對我們的目的資料做 `MODEL`,`MODEL`意思是將已經知道的值輸入進去給演算法,然後對新的值做預測,上述的『黃色』以及『紫色』的點就是所謂的 `MODEL`。 | ||
|
|
||
| 我們將三頁的資料做成 MODEL ,將網狀座標利用我們的 MODEL 做預測,不同的欄位用不同的顏色來表示,跑出N在不同的值下,所產生的結果如下 | ||
|
|
||
|  | ||
|  | ||
|  | ||
|  | ||
|  | ||
|
|
||
|
|
||
| 這裡可以看出 N 在 1~2 之間的效果會比 4 以上效果來得好,我們可以利用畫出來的結果來決定使用的 N 值 | ||
| 然而這只有三頁的資料,就可以產生相當程度的分類,機器學習的前途果然不可限量啊!! | ||
{kind=link}
Loading
Sorry, something went wrong. Reload?
Sorry, we cannot display this file.
Sorry, this file is invalid so it cannot be displayed.
{kind=link}
Loading
Sorry, something went wrong. Reload?
Sorry, we cannot display this file.
Sorry, this file is invalid so it cannot be displayed.
{kind=link}
Loading
Sorry, something went wrong. Reload?
Sorry, we cannot display this file.
Sorry, this file is invalid so it cannot be displayed.
{kind=link}
Loading
Sorry, something went wrong. Reload?
Sorry, we cannot display this file.
Sorry, this file is invalid so it cannot be displayed.
{kind=link}
Loading
Sorry, something went wrong. Reload?
Sorry, we cannot display this file.
Sorry, this file is invalid so it cannot be displayed.
{kind=link}
Loading
Sorry, something went wrong. Reload?
Sorry, we cannot display this file.
Sorry, this file is invalid so it cannot be displayed.
{kind=link}
Loading
Sorry, something went wrong. Reload?
Sorry, we cannot display this file.
Sorry, this file is invalid so it cannot be displayed.
{kind=link}
Loading
Sorry, something went wrong. Reload?
Sorry, we cannot display this file.
Sorry, this file is invalid so it cannot be displayed.
{kind=link}
Loading
Sorry, something went wrong. Reload?
Sorry, we cannot display this file.
Sorry, this file is invalid so it cannot be displayed.
Add this suggestion to a batch that can be applied as a single commit.
This suggestion is invalid because no changes were made to the code.
Suggestions cannot be applied while the pull request is closed.
Suggestions cannot be applied while viewing a subset of changes.
Only one suggestion per line can be applied in a batch.
Add this suggestion to a batch that can be applied as a single commit.
Applying suggestions on deleted lines is not supported.
You must change the existing code in this line in order to create a valid suggestion.
Outdated suggestions cannot be applied.
This suggestion has been applied or marked resolved.
Suggestions cannot be applied from pending reviews.
Suggestions cannot be applied on multi-line comments.
Suggestions cannot be applied while the pull request is queued to merge.
Suggestion cannot be applied right now. Please check back later.
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
有沒有客戶資料隱私的疑慮呢?需不需要把名字用星號處理過?