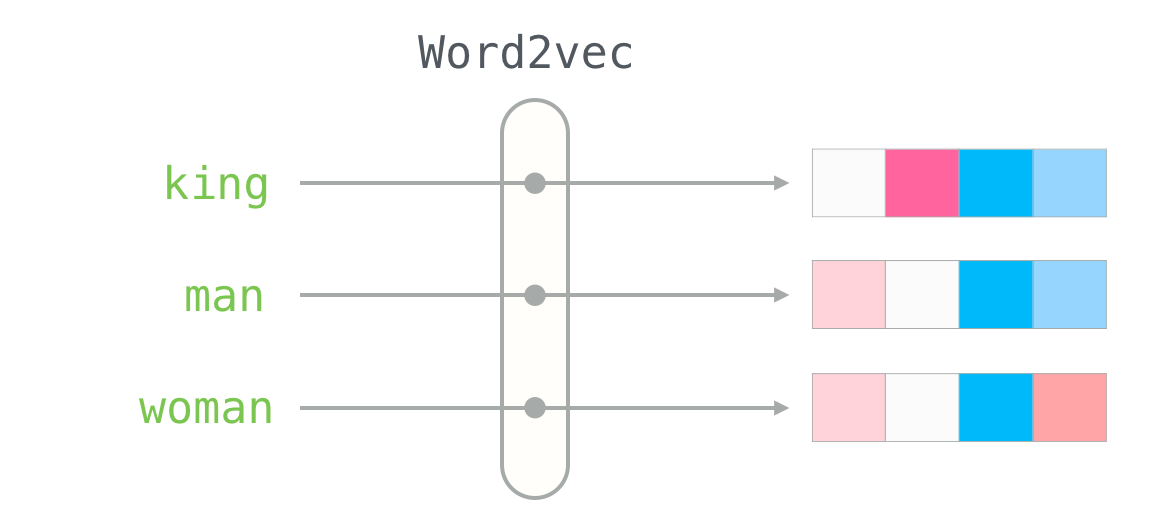
The Word2Vec algorithm, published in 2013, uses a neural network model to learn word associations from a large corpus of text. To do so, Word2Vec represents each unique word of the corpus as a vector. Using thoses vectors, we can compute the cosine similarity between them to determine the sementic similarity level between words.
Usuallay, this algorithm is used to deal with Natural Language Processing problems. However, we can use it in several ways as most of AI algorithms. Here, I decided to use it to build a content based recommender system. Indeed, if we take the orders history of a client it represents a sequence or a list of several items as a sentence is a sequence of words. In our case, we will compute a vector for each unique items and then we can measure similarity between them or a list of items to define similar products.