
备份你的维基点



本项目停止支持,详见这里。
English | Русский язык | 繁體中文 | More...
这是用来创建一个爬虫工程,用于爬取wiki上存在的所有页面,用于在受灾后的网站静态只读版本。可能不适用于恢复工程,但是为恢复页面提供了依据。 目前来说,这适用于所有Wikidot网站,但是为了防止恶意爬虫,任何网站必须有/system:list-all-pages页面才可以爬。
在你的网站URL/system:list-all-pages上建立一个页面,添加 [[module Pages preview="true"]] 代码
请点击侧栏Releases中显示的最新版,选择"Source Code"下载。
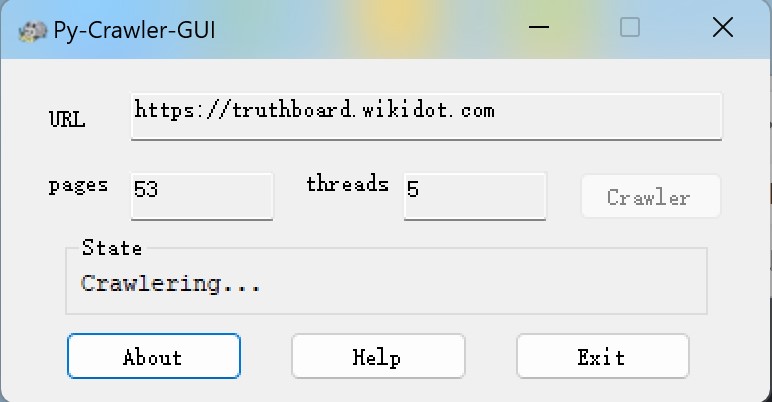
- 运行时启用PyCrawlerGUI.exe。
- 在URL处输入你的网址,点击确认。
- 去查看你的网站URL/system:list-all-pages页面下面显示的page X of X的后面一个数(在本例子中就是后面一个x)
- pages处输入这个数【如果你填多了(设这个数为X,X≠0),它会输出1~X的HTML文件(名称为pages1~pagesX.html)但是(X-1)和X是同一个】,然后换行。
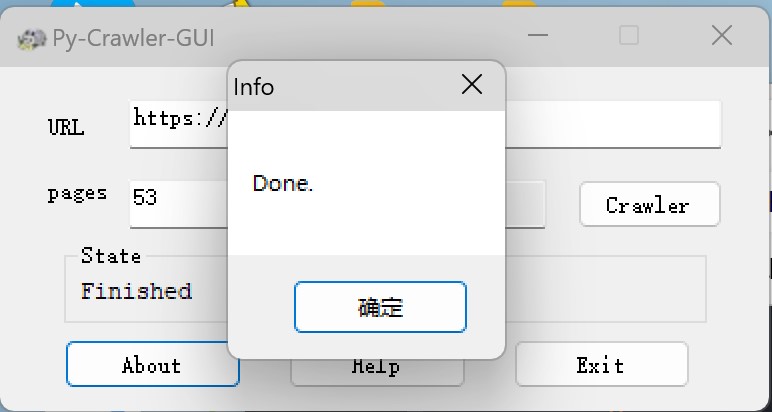
- 静静等待程序执行完毕吧,会有弹窗提示的。
- 完成了?记得把html文件夹移动一下,避免混淆。

遇到了错误或BUG? 来 这里 反馈。
有新功能的想法,但是不知道在那里反馈? 来 这里反馈。
你可以给我们提供技术帮助? 来 这里 拉取分支进行修改吧。
Copyright (c) 2022-2023 HelloOSMe
All Rights Reserved.
版权所有 (c) 2022-2023 HelloOSMe
保留所有权利。
The icon "Py-Crawler-worm" is made by hatoyama_kumiko and is applicable to CC-BY-SA-4.0 protocol.
The application made by RedPanda Dev-Cpp , Visual Basic 6.0 and Windows Notepad.