In this project, we aim to develop an application that recommends research papers extracted from arXiv.org based on users' preference data.
arXiv is an open-access online repository of papers that expands across a vast range of fields in science and engineering and keeps its readers updated with the most recent publications. However, one shortcoming of it is the lack of a recommendation mechanism that minimizes its users' effort to navigate through countless papers. Each time the user clicks on the link to a particular field of interest, they are directed to the entire repository of papers instead of being recommended with a subset of them that match the user's interest the most, which adds certain difficulty to the users' experience. Therefore, the core user need we aim to address is to help users easily get recommendations for research papers they are interested in. More specifically, the application should be able to...
- search through arXiv.org and make recommendations based on the user's preference
- allow the user to create an account and save papers that they find useful
- automatically recommends papers based on the ones the user saved in their last login
- allow the user to rate a particular paper so that the system can learn their preference and make recommendations more precisely next time
Some proposed entities that can fit into the purpose of this system are the following:
- User
- Username
- Password hash
- A list of preferred paper categories
- Saved papers
- Papers upvoted
- Papers downvoted
- Research Paper
- Author
- Category of the paper
- Date of publish
- Abstract
- Link to the actual paper
- Paper's ID in the online repository (i.e., arXiv.org)
- Count of upvotes
- Count of downvotes
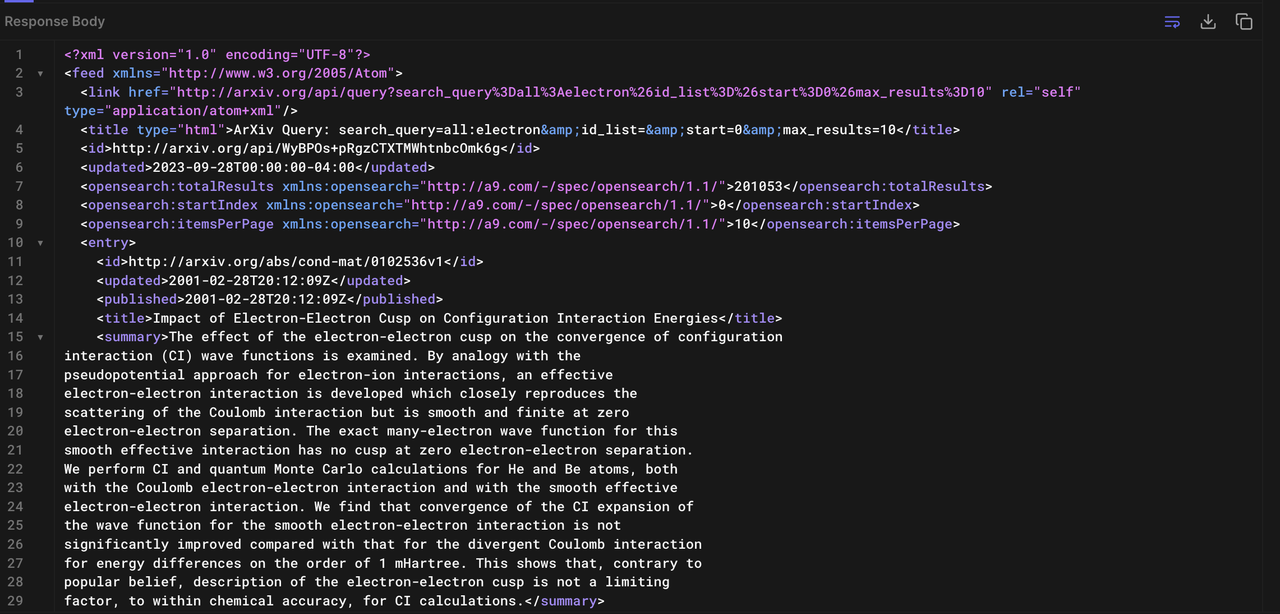
Exploring the API provided by arXiv, we notice that papers are categorized in terms of the field they belong to. By querying papers from a specific category, we are able to obtain data of a customizable number of papers presented in the Atom 1.0 format. For example, using Hoppscotch, an open-source web-based API development suite, we made a query to arXiv that retrieved the first ten results that matched the query all:electron using the URL http://export.arxiv.org/api/query?search_query=all:electron&start=0&max_results=10. The partial response from the API is shown in the following screenshot. For the full response, please refer to the file api_query_demo.
Looking ahead, a missing element that is of fundamental importance is defining a measurement that captures the degree of matching between a user's preference data and the data that characterizes a given paper. We are currently in discussion on designing a reasonably effective way to resolve this issue by investigating more deeply the parameters attached to each paper of interest.