"대화가 잘 통하는" 챗봇 같은 경우, 주로 대용량의 데이터 베이스에 사람들의 일상 대화 내용이나 사람이 직접 입력한 대화를 정리 한 후 인풋으로 들어온 대화의 맥락에 맞는 단어나 문장을 골라내는 방식으로 구현됩니다. 하지만 이런 모델 같은 경우 대용량의 데이터베이스를 하나하나 검수하기 힘들다는 점, 크롤링한 대화를 이용한 경우 실제 개인정보가 유출될 수 있다는 점 등이 문제가 되기도 하는데, 그래서 RNN팅은 seq2seq 인코더 디코더 구조를 이용한 생성 모델링을 시작했습니다.
이러한 챗봇 모델링이 일상에서 누군가와 끊임 없이 대화 하고 싶은 사람, 시시콜콜한 이야기를 나누고 싶은 사람, 교류를 원하는 사람들의 감정을 알아주고 더 나아가 소통이 단절된 사회에 도움이 될 것이라고 생각하며 프로젝트를 시작했습니다.
chatbot 구현 참고자료
해당 튜토리얼을 보고 구현에 참고하였으며, 전처리 파트는 다른 방법으로 수행했습니다.
자세한 데이터는 여기를 클릭해주세요 !_AI 허브 웰니스 대화 스크립트
자세한 데이터는 여기를 클릭해주세요 !_한국어 챗봇 데이터셋
그 외에도 직접 본인의 대화를 크롤링, 감성대화 말뭉치 등 다양한 '감정공감' 데이터를 이용했습니다.
| 데이터 예시입니다 | 질문과 답변으로 구성되어 있습니다 | 간단한 일상 대화, 감정 공감에 집중한 데이터를 가져왔습니다. |
|---|---|---|
| 1 | 가상화폐 쫄딱 망함 | 어서 잊고 새출발하세요. |
| 2 | 가스비가 너무 많이 나옴 | 다음 달에는 더 절약해봐요 |
| 3 | 눈 앞이 깜깜할 때도 있어요 | 그랬군요. 제가 당신 마음을 조금 더 이해할 수 있으면 좋겠어요. |

데이터 전처리 과정이 가장 중요했습니다. 문장부호 등을 제거한 전처리한 대화집을 txt 형태로 바꾸어 토큰화 한 후 1번 이상 나온 단어에 대해서 단어집을 만들고, 그 단어에 인덱스를 부여해 토큰화된 문장에 인덱스를 부여했습니다. 인덱스 부여 후 이를 텐서로 변환해서 이용했습니다. 이때 seq2seq은 문장의 입력 길이가 같아야하기에 padding 을 추가해주어야하고 문장의 시작과 끝을 명시해야하기 때문에 eos token, sos token, pad token 등 특수 토큰을 단어집에도 추가하고 문장에도 추가해 주었습니다.
참고논문_Sequence To Sequence Learning With Neural Networks
참고논문_Attention Is All You Need
위 논문에서 나오는 사진과 자료 이용했습니다. 문제시 삭제하겠습니다.
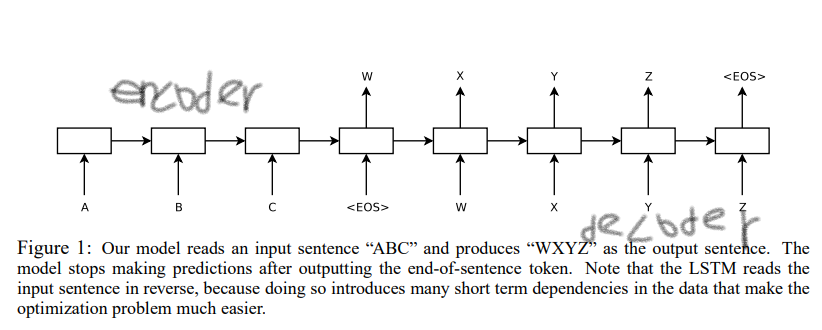
Encoder ⇨ 순차적으로 입력 받은 단어정보를 압축해서 context vector 생성 ⇨ Decoder ⇨ 단어를 한 개씩 출력, end token 이 나오기 전까지 수행
기본 모델로 seq2seq을 이용하고 이후 결과를 보고 global attention 을 추가로 구현했습니다.
-
양방향 GRU 를 2층 사용
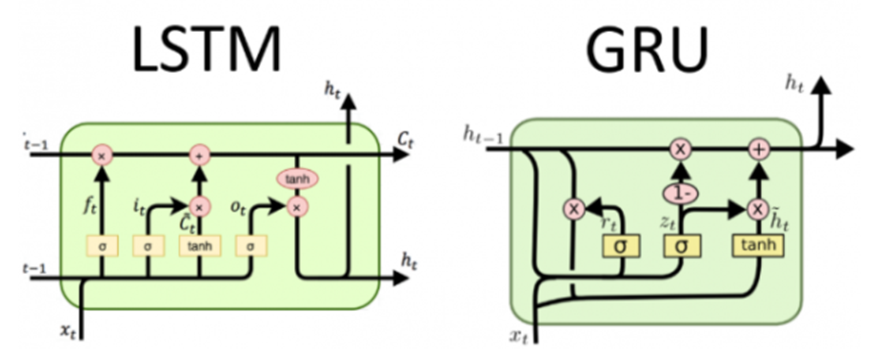
기존의 lstm모델은 cell state에서 forget, input, output 세 개의 gate를 활용하여 어떤 정보를 기억하고, 잊을지를 결정하였다면, gru모델은 reset gate와 update gate 두 개 만을 사용하여 정보를 처리함.두 모델 모두 성능은 좋지만, gate의 수가 하나 더 적은 gru에서 parameter 수가 더 적어지기 때문에 가벼운 모델을 위해 이용했습니다. 또한 기존 일방향 gru와 달리 양방향을 이용하면, 한 쪽에서는 순방향으로 단어를 넣어가며 학습하여 다음 단어에 대해 이전 까지의 정보를 이용할 수 있고, 다른 쪽에서는 역방향으로 단어를 넣어가며 학습하여 앞으로 나올 정보들을 이용해 학습이 진행되기때문에 전체 문맥을 더 잘 파악할 수 있다고 판단했습니다. 순방향 학습 후 역방향 학습을 진행, 그 후 이 둘을 합산해 두번째 GRU레이어로 보내기 때문에 총 4개의 hidden stage를 이용한 효과를 낼 수 있다고 생각했습니다. -
Global attention 이용
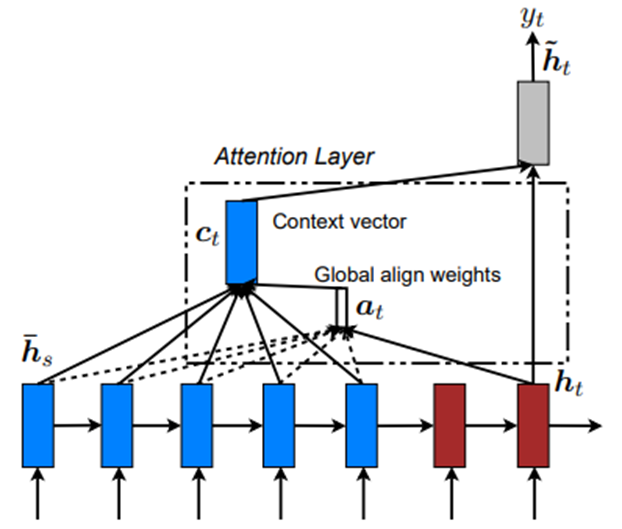
Local과 달리 encoder에 넣어 준 단어 전체에 대해, 즉 모든 time step의 hidden을 고려하여 context vector를 계산합니다. -
Global attention 의 계산 방법을 세가지 구현 여기서 어텐션벡터 a의 계산 방법은 논문에서는 세 가지 방식이 구현되어 있습니다. 코드로 보겠습니다.
class Attn(nn.Module):
def __init__(self, method, hidden_size):
super(Attn, self).__init__()
self.method = method
if self.method not in ['dot', 'general', 'concat']:
raise ValueError(self.method, "is not an appropriate attention method.")
self.hidden_size = hidden_size
if self.method == 'general':
self.attn = nn.Linear(self.hidden_size, hidden_size)
elif self.method == 'concat':
self.attn = nn.Linear(self.hidden_size * 2, hidden_size)
self.v = nn.Parameter(torch.FloatTensor(hidden_size))
이 부분부터 보시면, 어텐션 V의 계산 방법 3가지를 모두 구현했고, 저희는 메인 모델에서 내적 방법을 사용했습니다
def dot_score(self, hidden,encoder_output):
return torch.sum(hidden * encoder_output, dim=2)
def general_score(self, hidden, encoder_output):
energy = self.attn(encoder_output)
return torch.sum(hidden * energy, dim=2)
def concat_score(self, hidden, encoder_output):
energy = self.attn(torch.cat((hidden.expand(encoder_output.size(0), -1, -1), encoder_output), 2)).tanh()
return torch.sum(self.v * energy, dim=2)
즉 , 기본 seq2seq 모델의 구조를 약간 바꾸고 어텐션을 추가하는 방법으로 구현을 하였습니다.
| Hyperparameters | 내용 |
|---|---|
| Loss | 다양한 단어들에 대해 확률을 계산하여 Cross Entropy 사용 |
| Optimizer | Adam |
| Hidden Size | 256 |
| Batch Size | 128 |
| Dropout | 0.2 |
| Learning Rate | 0.001 |
| Decoder Ratio | 10 |
| Max Length | 8 |
최종 모델의 하이퍼파라미터 입니다.
특히 최대 문장 길이를 조정하는 MAX_LENGTH 라는 하이퍼파라미터를 적극 활용하여 너무 긴 문장은 제외하는 등 학습의 속도를 높혔습니다.



모델 학습 후 평가 결과입니다. 구현을 목적으로 두어서 평과 결과가 그다지 좋지 않지만, 데이터 셋과 비슷한 단어가 들어왔을 때 적절한 대화를 생성했습니다. 토큰화와 단어집 만들기를 space 기준으로 했기 때문에 문장이 어색한 부분이 다수 보입니다. 후에는 형태소 분석기를 이용하는 방향으로 발전시킬 수 있겠습니다.