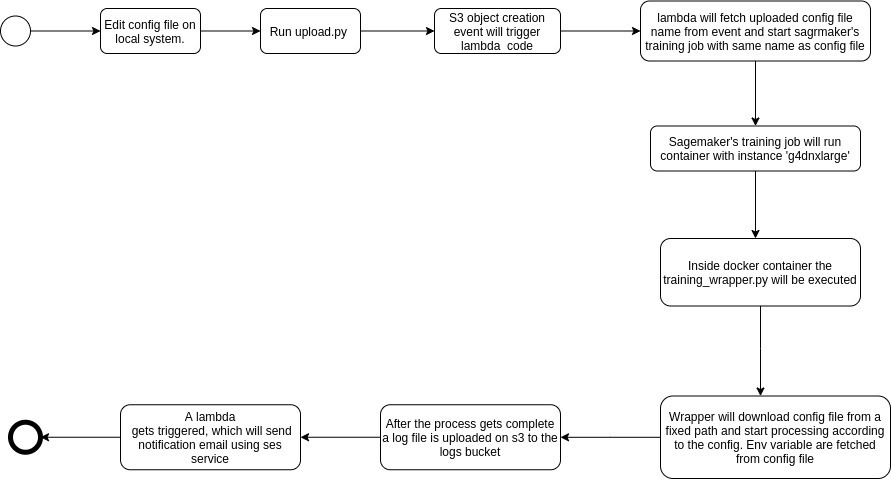
Model Training Workflow
- Workflow for model training.
- To train a model for object detection there are certain steps that need to process one by one.
- This workflow is to automate that process using a python wrapper.
- The steps involved in model training are:
- Generate tf-record formate of training data and testing data.
- Downloading base model files.
- update the training config file for the path, steps, learning rate..etc.
- start model training.
- Running evaluation with the latest checkpoint.
- Freezing the model.
- The naming convention of the output_dir is: "(model_version)_(architecture_name)"
- The output file contains the following files and directory:
- checkpoint for each iteration of dataset except for the last one as it is already in the training folder
- Frozen graph file.
- Eval dir containing tensorboard events for evaluation and visualization on test data.
- Meta_data.txt having meta-information about the model.
- evaluation_results.json having evaluations matrices.
- model training config file.
- commands.txt having commands to train model locally but it requires path update.
List of available architecture on s3:
- faster_rcnn_inception_resnet_v2_atrous_coco(batch size -1)
- faster_rcnn_resnet101_coco_model(batch size -1)
- ssd_resnet50_fpn_coco_model(batch size-1)
- ssd_inception_v2_coco_model(batch size - 16)
- rfcn_resnet101_coco_model(batch size - 1)
- faster_rcnn_resnet50_coco_model(batch size - 1)
- faster_rcnn_nas(batch size-1)
- ssd_mobilenet_v1_coco(batch size -16)
- ssd_mobilenet_v2_coco(batch size -16)
- ssd_mobilenet_v1_fpn_coco_model(batch size- 16)
- faster_rcnn_resnet101_kitti(batch size - 1)